





E-Commerce Proxies for Competitive Intelligence: 2026 Guide
Amazon prices change 2.5 million times per day. Learn how a competitive intelligence proxy gives e-commerce teams the data to track competitors, protect margins, and respond faster.

Table of Contents
- Why E-Commerce Competitive Intelligence Requires Proxies?
- Competitive Intelligence Proxy Use Cases in E-Commerce?
- Competitor Price Tracking: Proxy Configuration for Real-Time Monitoring?
- Product Assortment and Listing Monitoring with Proxies?
- Promotional and Content Surveillance: What Competitors Are Saying?
- Sizing Your Proxy Pool for E-Commerce Competitive Intelligence?
- Conclusion
-
Why E-Commerce Competitive Intelligence Requires Proxies?
Amazon prices change up to 2.5 million times per day (Profitero, 2023). For any e-commerce team trying to stay price-competitive without sacrificing margin, manual monitoring isn't a strategy — it's a way to always be reacting to data that's already hours old. The companies that win on pricing respond in minutes, not days, because they've automated competitive data collection at scale.
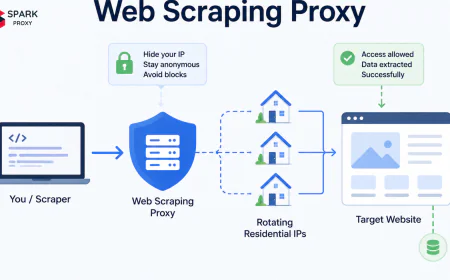
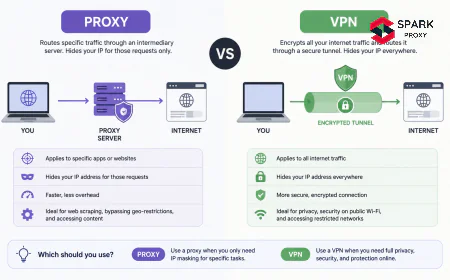
That automation runs on proxies. A competitive intelligence proxy distributes data collection requests across rotating IP pools so e-commerce sites never see enough requests from a single address to trigger rate limits or blocks. Without that infrastructure layer, automated competitor monitoring breaks down within the first hour of a collection run.
This guide covers how e-commerce companies use competitive intelligence proxies across price monitoring, product assortment tracking, promotional surveillance, and market positioning — and how to configure each use case reliably.
Key Takeaways
- Amazon changes prices up to 2.5 million times per day (Profitero, 2023); manual competitor monitoring produces data that's irrelevant before it's acted on
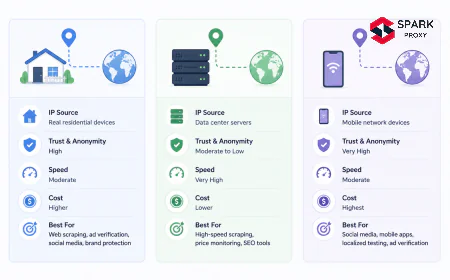
- Rotating datacenter proxies achieve 94% data completeness for e-commerce competitive monitoring (Oxylabs, 2024), at 4-6x the speed and one-fifth the cost of residential alternatives
- Companies using automated competitive intelligence reduce competitive response time by 35% (Forrester, 2023) and report 12-18% improvement in margin capture (McKinsey, 2024)
92% of Fortune 500 companies practice formal competitive intelligence (Crayon, 2024). In e-commerce specifically, the companies doing this at any meaningful scale are running automated collection — not because it's faster than manual research, but because the data they need changes faster than any human can track.
78% of retailers now adjust prices daily based on competitive data (Prisync, 2024). Daily adjustment means daily data collection across potentially hundreds of competitor SKUs. For a mid-size e-commerce operation with 5,000 tracked SKUs across 10 competitors, that's 50,000 price checks per day. At a conservative 3KB per page, that's 150MB of data — manageable volume, but only if the collection infrastructure stays unblocked.
Without proxies, automated competitive monitoring breaks within hours:
Rate limits accumulate fast: E-commerce sites block IPs after 80-150 requests per hour on average (Apify, 2023). A 50,000-check daily run from one IP requires roughly 2,000 requests per hour over a 24-hour window — 13-25x above most retail site thresholds. The IP gets blocked in the first session, and subsequent attempts from the same address return 429s or redirect to CAPTCHAs.
Geo-pricing distorts the data: Major retailers serve different prices based on visitor location. A competitor's price in Germany may differ from their price for US customers by 10-25% — not currency conversion, but market-specific pricing strategy. Collecting from a single geographic IP produces systematically wrong price comparisons if your business and your competitors operate across markets.
Session detection degrades data quality: Modern retail sites use session tracking to identify bot behavior. Requests without proper cookie state, or that access product pages without passing through a search or category page, return stale cached prices or trigger JavaScript challenges that block data extraction.
What we've found: The session detection problem causes more silent data quality failures than outright blocks. A blocked request returns an error — you know data is missing. A session-invalidated price fetch returns a stale cached price that looks like valid data. Teams that don't validate against known reference prices often discover they've been storing systematically incorrect competitor prices for weeks before the problem surfaces.
-
How Retail Sites Detect and Block Competitive Scrapers
Retail bot detection operates at three layers. IP-level rate limits are the surface layer — high volume from one address triggers throttling or blocks. Behavioral analysis is the middle layer — request patterns without natural browsing behavior (search → category → product → cart) indicate automation. JavaScript fingerprinting is the deepest layer — sites that render prices in JavaScript require execution to return real data, and headless requests without proper JS execution return skeleton pages.
The good news for competitive intelligence: most retail sites focus bot detection on cart operations and checkout flows, where fraud risk is high. Product listing pages, search results, and price displays are less aggressively protected — the primary countermeasure is IP-level rate limiting, which proxy rotation directly addresses.
how to avoid getting your proxy blocked
-
Competitive Intelligence Proxy Use Cases in E-Commerce?
The global competitive intelligence market is worth $7.2 billion in 2024, growing toward $12.5 billion by 2030 (MarketsandMarkets, 2024). E-commerce is the largest single vertical driving this growth, because online retail produces structured, machine-readable competitive data that can be collected and acted on far faster than traditional intelligence methods.
Proxy-backed competitive intelligence in e-commerce covers four distinct use cases, each with different data collection requirements:
1. Price monitoring: The highest-frequency use case. Tracking competitor prices across SKUs on a scheduled basis — hourly, daily, or on-event (when your own prices change). This is the use case that justified the initial infrastructure investment at most e-commerce companies. It requires fast, high-volume collection where datacenter proxies outperform residential on speed and cost.
2. Product assortment tracking: Monitoring which products competitors carry, how their catalog is structured, which categories are expanding or contracting, and how they handle out-of-stock items. Lower frequency than price monitoring (daily or weekly sweeps vs. hourly price checks), but higher data volume per run because full catalog pages need to be parsed.
3. Promotional and content surveillance: Tracking when competitors run sales, what messaging they use, how they position products in paid and organic search, and how their ad creative changes over time. This use case often involves monitoring competitor landing pages, ad libraries, and search result positioning — which has overlap with SEO competitive intelligence.
4. Inventory and stock monitoring: Tracking competitor inventory levels, identifying when they're running low on key SKUs (an opportunity to capture demand), and monitoring restocking patterns. Some retail sites surface inventory indicators in their product pages; others require inference from add-to-cart behavior or delivery estimate changes.
Source: Crayon, 2024; Prisync, 2024. Adoption rates among e-commerce teams running automated competitive intelligence programs.
-
Competitor Price Tracking: Proxy Configuration for Real-Time Monitoring?
Competitor price tracking is the highest-frequency use case and the one that demands the most from proxy infrastructure. 78% of retailers adjust prices daily based on competitive data (Prisync, 2024), but the retailers with a meaningful edge are adjusting in near-real-time — within minutes of a competitor price change on a key SKU.
Rotating datacenter proxies achieve 94% data completeness for e-commerce competitive monitoring (Oxylabs, 2024) and are the standard choice for price tracking workloads. They're 4-6x faster than residential proxies for structured page fetches and cost significantly less per GB — critical at the volumes price monitoring generates.
A production price monitoring setup with random rotation and per-source rate control:
```python
import requests
import random
import time
from collections import defaultdict
from datetime import datetime, timedelta
PROXY_POOL = [
"http://user:pass@dc-proxy1:port",
"http://user:pass@dc-proxy2:port",
"http://user:pass@dc-proxy3:port",
... expand to full pool
]
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,/;q=0.8",
}
Track per-IP request counts and cooldown state
ip_state = {p: {"requests_this_hour": 0, "cooldown_until": datetime.min} for p in PROXY_POOL}
hour_start = datetime.now()
def reset_hourly_counts():
global hour_start
if (datetime.now() - hour_start).seconds >= 3600:
for p in ip_state:
ip_state[p]["requests_this_hour"] = 0
hour_start = datetime.now()
def get_proxy(max_per_hour=80):
reset_hourly_counts()
now = datetime.now()
available = [
p for p, s in ip_state.items()
if s["requests_this_hour"] < max_per_hour and s["cooldown_until"] <= now
]
if not available:
raise RuntimeError("All proxies at hourly limit or in cooldown")
proxy = random.choice(available)
ip_state[proxy]["requests_this_hour"] += 1
return proxy
def fetch_product_price(url):
proxy = get_proxy()
try:
resp = requests.get(
url,
proxies={"http": proxy, "https": proxy},
headers=HEADERS,
timeout=15,
)
if resp.status_code in (429, 403):
ip_state[proxy]["cooldown_until"] = datetime.now() + timedelta(minutes=45)
return None
return resp.text
except requests.RequestException:
ip_state[proxy]["cooldown_until"] = datetime.now() + timedelta(minutes=30)
return None
Randomized delay between requests
time.sleep(random.uniform(1.0, 2.5))
```
-
Handling Dynamic Pricing and Session-Based Price Variants
Major retailers — Amazon, Walmart, Target — use dynamic pricing that can serve different prices to the same product URL depending on session state, browsing history inference, and account type. An anonymous first-visit request to a product page may see a different price than a returning session, or a price that's only shown after passing through a search result.
Three approaches that improve price data accuracy under dynamic pricing conditions:
Clean session initialization: For each price check, initialize a fresh session starting from the site's homepage or a category page before navigating to the product URL. This mimics first-visit behavior and avoids the behavioral flags that accumulate across repeated direct-URL access patterns.
Geo-matched proxies for market prices: Use proxies registered in the same market as your target customers. If you're monitoring US competitor prices for a US audience, US-geolocated datacenter proxies produce the prices your customers actually see — not the prices the retailer shows to European traffic.
Reference price validation: Maintain a small set of known reference prices (products you also sell, where you know the correct competitor price from manual spot-checks) and validate your automated collection against these on each run. Systematic divergence from reference prices signals a collection accuracy problem before it corrupts your pricing decisions.
What we've found: The 6% that rotating datacenter proxies miss in completeness (94% vs. 100%) is almost never uniformly distributed. It concentrates on specific competitor sites with stricter detection. Running completeness reports per source domain — rather than aggregate — surfaces which competitors need dedicated proxy pools or residential IPs, and which are being fully collected with standard rotation.
competitor price tracking setup
-
-
Product Assortment and Listing Monitoring with Proxies?
Competitor price monitoring tells you what something costs. Product assortment monitoring tells you what they're selling. These are distinct competitive questions that often require different collection strategies.
Assortment monitoring covers: which SKUs competitors carry, which categories are expanding (new product launches, increased SKU depth), which are contracting (discontinuations, out-of-stocks becoming permanent), how competitors handle variant structure (color/size options), and where they position products in their own site search and category pages.
For a retailer managing 50,000 SKUs, tracking even 5 competitors' full catalogs at weekly frequency means indexing and comparing 250,000 product listings per week. At that scale, the collection infrastructure needs to handle:
- Pagination: E-commerce category pages typically show 24-48 products per page. A competitor with 10,000 SKUs in a category requires 200-400 paginated requests to collect the full listing — all from the same site, which requires careful per-site rate management
- Variant handling: Products with multiple variants (sizes, colors) are sometimes listed as individual SKUs and sometimes as a single product page. Collection logic needs to normalize this to compare assortments accurately
- Change detection: Efficient assortment monitoring stores a hash of the last-seen state for each product listing and only fetches full page content when the hash changes — reducing total request volume significantly on stable competitor catalogs
Proxy configuration for assortment monitoring is less rate-sensitive than price monitoring (you don't need hourly freshness) but more volume-intensive per run. A weekly full-catalog sweep across 5 competitors at 1,000 category pages each = 5,000 paginated requests, typically spread over a multi-hour collection window.
| Monitoring Type | Check Frequency | Requests per SKU/Run | Proxy Type |
|---|---|---|---|
| Price monitoring (key SKUs) | Hourly | 1 direct URL fetch | Datacenter (rotating, high-speed) |
| Price monitoring (full catalog) | Daily | 1 per SKU | Datacenter (rotating) |
| Assortment / catalog crawl | Weekly | 1-3 (listing + detail) | Datacenter (rotating) |
| Promotional page monitoring | Daily or on-event | 2-5 (landing pages + search) | Datacenter (rotating) |
| Inventory level inference | Daily | 1-2 per SKU | Datacenter (rotating) |
| Ad content / search position | Daily | 2-4 (search + ad endpoints) | Datacenter (rotating) |
-
Promotional and Content Surveillance: What Competitors Are Saying?
Companies using automated competitive intelligence reduce competitive response time by 35% (Forrester, 2023). A meaningful portion of that advantage comes not from price data but from promotional intelligence: knowing when a competitor launches a sale before your customers do, seeing how they're positioning a new product category, and understanding what messaging they're testing in paid ads.
Promotional surveillance covers:
Sale and discount event tracking: Monitoring competitor homepage banners, sale pages, and promotional landing pages for discount events. Retailers that spot a competitor's flash sale within minutes can respond with targeted promotions to at-risk customer segments, rather than discovering the sale after it's driven overnight customer acquisition.
Search result positioning: Tracking where competitors appear in organic and paid search for your target keywords, and how their ad creative changes over time. This uses SERP proxy infrastructure (same as SEO rank tracking) but targeted at competitive keyword sets rather than your own rankings.
PDP content changes: Product Detail Page content changes — new images, updated bullet points, new badge placement — often signal competitive repositioning. Monitoring PDP content hashes detects these changes without requiring full-page re-analysis on every collection cycle.
Marketplace presence: For brands selling on Amazon, Walmart Marketplace, or other platforms, tracking competitor listings on those platforms provides intelligence on pricing, review velocity, and promotional activity in the same channel where your customers are comparing options.
For promotional surveillance, the proxy configuration challenge is breadth rather than frequency. You're monitoring more distinct URLs and sites than price monitoring, but at lower per-URL frequency. Shared rotating pools handle this well — the per-site rate stays low because each site is only checked once or twice per day.
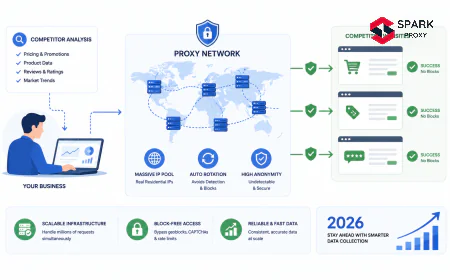
Source: Forrester, 2023; McKinsey, 2024; Oxylabs, 2024. Metrics for e-commerce teams: competitive response time, margin capture improvement, and SKU price coverage rate. ecommerce competitive intelligence guide
-
Sizing Your Proxy Pool for E-Commerce Competitive Intelligence?
Pool sizing for competitive intelligence differs from single-use-case scraping because the workload is mixed: high-frequency price checks running continuously alongside lower-frequency assortment crawls and on-event promotional checks. The pool needs to handle simultaneous demands without one use case starving another.
Base sizing formula:
- Price monitoring load: (SKU count × check frequency per hour) ÷ (per-IP hourly limit)
- Example: 5,000 SKUs × 2 checks/hour ÷ 80 requests/IP/hour = 125 IPs for price monitoring alone
- Add 30-40% for assortment crawls and promotional surveillance running in parallel
- Add 20% buffer for blocks, retries, and cooldowns
Practical pool estimates by program size:
| Program Scale | Tracked SKUs | Competitors | Daily Requests | Recommended Pool |
|---|---|---|---|---|
| Small retailer / brand | 500-2,000 | 2-5 | 10K-50K | 20-80 IPs |
| Mid-size retailer | 2,000-10,000 | 5-10 | 50K-250K | 80-400 IPs |
| Large retailer / marketplace | 10,000-100,000 | 10-20 | 250K-2.5M | 400-3,500 IPs |
| Enterprise / price intelligence platform | 100,000+ | 20+ | 2.5M+ | 3,500+ IPs |
Source-segmentation at scale: Once your program exceeds 5-10 competitor sources, segment your proxy pool by source. Allocate dedicated IP blocks per major competitor site. This prevents a block event on Amazon from consuming pool capacity needed for Walmart or Target monitoring, and allows per-source tuning of rotation speed to match each site's specific rate limits.
E-commerce businesses tracking competitors with proxies report 12-18% improvement in margin capture (McKinsey, 2024). At mid-size retailer scale ($10M+ revenue), a 15% margin improvement on competitive SKUs justifies significant proxy infrastructure investment. The proxy cost is rarely the constraint — it's the data pipeline and pricing algorithm downstream that determines ROI.
Scale Your Competitive Intelligence Without Gaps
SparkProxy's datacenter proxy pools are built for high-frequency e-commerce monitoring, with geo-targeted IPs across 40+ countries, per-source pool segmentation, and 94%+ data completeness on retail collection workloads.
-
Conclusion
E-commerce competitive intelligence at scale is a data infrastructure problem before it's a strategy problem. The competitive insight is only as good as the data pipeline behind it — and that pipeline breaks without proxies at the collection volumes that make the intelligence actionable.
The configuration is well-established: rotating datacenter proxies for high-frequency price monitoring, geo-matched to your target market, with per-source rate management and hourly limits tracked per IP. Add reference price validation to catch silent accuracy failures before they corrupt pricing decisions. Size your pool for 120-140% of normal monitoring volume to handle spikes without degrading coverage.
Companies that get this right close the competitive response gap — from hours or days to minutes. The 35% reduction in response time (Forrester, 2023) and 12-18% margin improvement (McKinsey, 2024) aren't from better strategy. They're from having accurate, fresh, complete competitive data when pricing decisions get made.
Frequently Asked Questions
A competitive intelligence proxy is an IP address used to route automated data collection requests so competitor sites see traffic from different users and locations rather than a single server. For e-commerce, it enables continuous price monitoring, product assortment tracking, and promotional surveillance without triggering the rate limits and IP blocks that retail sites apply to high-frequency automated access.
[INTERNAL-LINK: competitive intelligence tools guide → overview of tools and infrastructure for e-commerce competitive monitoring]
For most e-commerce competitive intelligence workloads, datacenter proxies are sufficient. They achieve 94% data completeness on retail monitoring tasks (Oxylabs, 2024) and are 4-6x faster and significantly cheaper than residential alternatives. Residential proxies are needed for specific cases: sites that categorically block datacenter IPs, or when you need hyper-accurate geo-specific pricing that requires a residential IP signature in the target market.
It depends on your market and pricing strategy. For categories with frequent price changes (consumer electronics, fast fashion, commodity products), hourly monitoring on key SKUs is standard. For categories with stable pricing, daily checks are sufficient. Amazon's pricing changes 2.5 million times per day across its catalog (Profitero, 2023) — if you compete with Amazon on price-sensitive SKUs, hourly or near-real-time monitoring is the baseline.
Collecting publicly available competitor data through proxies is legal in most jurisdictions. US courts have ruled that scraping publicly accessible web content doesn't violate the Computer Fraud and Abuse Act. The constraints are: data must be publicly accessible without login, you must not bypass technical access controls like CAPTCHAs through unauthorized means, and collection of personally identifiable data triggers GDPR and CCPA obligations. Consult legal counsel for your specific use case.
Implement reference price validation: maintain a set of known competitor prices verified manually, and compare automated collection against these on each run. Track completeness per source domain — not just overall — to identify which competitor sites have collection gaps. Systematic divergence between automated and reference prices signals either session-detection issues (returning cached prices) or geo-mismatch (collecting prices for the wrong market).