

How to Avoid Getting Your Proxy Blocked
Avoid proxy blocks with TLS fingerprint matching, realistic headers, and crawl rate control. Proxy detection bypass for Python and browser automation.

Table of Contents
- Why Proxies Get Blocked: The Full Picture {#why-blocked}
- Rotate Proxies to Avoid Rate Limits {#rotate-proxies}
- Fix Your TLS Fingerprint (JA3/JA4) {#tls-fingerprint}
- Set Consistent HTTP Headers {#consistent-headers}
- Respect Crawl Rates and robots.txt {#crawl-rate}
- Handle Cookies and Sessions Correctly {#cookies-sessions}
- Avoid Common Bot Detection Signals {#bot-signals}
- Check for Proxy Header Leaks {#header-leaks}
- Test Whether You Are Being Detected {#detection-test}
- Common Blocking Patterns and How to Respond {#blocking-patterns}
- About the Author
-
Why Proxies Get Blocked: The Full Picture {#why-blocked}
Most people trying to avoid proxy blocks focus entirely on the IP — rotating more proxies, switching providers, trying residential instead of datacenter. That fixes maybe 30% of blocks. The other 70% come from fingerprinting signals that have nothing to do with the IP address. Cloudflare, Akamai, DataDome, and PerimeterX all fingerprint your TLS handshake, HTTP headers, and browser behavior before they even look at the IP. This guide covers every layer of proxy detection bypass — from TLS fingerprinting to cookie handling — with code for Python and browser automation.
Sites use multiple independent detection layers. A proxy can fail any one of them regardless of how clean the IP is:
| Detection Layer | What Is Checked | How to Pass |
|---|---|---|
| IP reputation | IP in blocklists, ASN flagged as datacenter | Use clean datacenter IPs; rotate frequently |
| TLS fingerprint (JA3/JA4) | TLS client hello parameters — cipher suites, extensions, curves | Match browser TLS fingerprint with curl_cffi or tls-client |
| HTTP headers | User-Agent, Accept, Accept-Language, Accept-Encoding consistency | Send a full, internally consistent browser header set |
| HTTP version | HTTP/1.1 vs HTTP/2 vs HTTP/3 | Use HTTP/2 (httpx) to match modern browsers |
| Request rate | Requests per second per IP | Add delays; rotate proxies per request or per domain |
| Cookie/session consistency | Same session ID, different IP = suspicious | Bind one proxy to one session; reset cookies with proxy |
| JavaScript / browser behavior | navigator.webdriver, canvas fingerprint, mouse events | Use undetected-chromedriver or Playwright with stealth patch |
| Proxy headers (X-Forwarded-For) | Real IP leaked in proxy headers | Use proxies that strip these headers |
Changing the proxy only fixes the first row. The others require changes to your HTTP client or browser configuration.
-
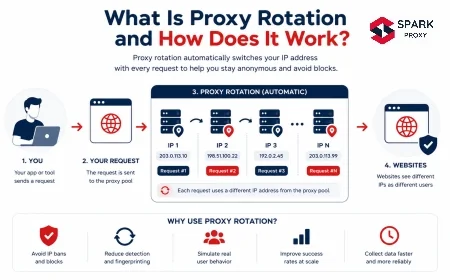
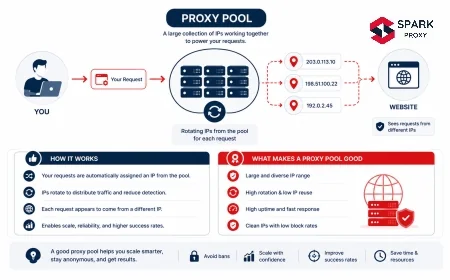
Rotate Proxies to Avoid Rate Limits {#rotate-proxies}
Rate-based blocks are the most common and the easiest to fix. A target site counts requests per IP per time window — typically 10–100 requests per minute before triggering a CAPTCHA or 429.
```python
import time
import random
import requests
PROXIES = [
"http://gateway.sparkproxy.io:10000",
"http://gateway.sparkproxy.io:10001",
"http://gateway.sparkproxy.io:10002",
]
def get(url: str, min_delay: float = 1.0, max_delay: float = 3.0) -> requests.Response:
proxy = random.choice(PROXIES)
resp = requests.get(
url,
proxies={"http": proxy, "https": proxy},
timeout=15,
)
time.sleep(random.uniform(min_delay, max_delay)) # Human-like pacing
return resp
```
Two rotation strategies and when to use each:
| Strategy | When to Use | Implementation |
|---|---|---|
| Per-request rotation | Stateless pages — product listings, search results |
random.choice(PROXIES)before each request || Per-session rotation | Login flows, multi-step checkouts, account-based scraping | One
requests.Sessionper proxy; do not rotate mid-session |
-
Fix Your TLS Fingerprint (JA3/JA4) {#tls-fingerprint}
This is the most overlooked aspect of proxy detection bypass. Every TLS client sends a "Client Hello" message at the start of an HTTPS connection. The combination of cipher suites, TLS extensions, elliptic curves, and signature algorithms in this message creates a fingerprint — JA3 (older) or JA4 (newer). This fingerprint is computed entirely from the network packet, not from any header your code sets.
Python's
requestslibrary usesurllib3under the hood, which has its own distinctive TLS fingerprint that matches no browser. Even if you setUser-Agent: Mozilla/5.0 (Chrome/124), the TLS fingerprint still says "Python/urllib3." Cloudflare and DataDome block on this mismatch.The fix:
curl_cffi— a Python binding to curl that impersonates the actual TLS fingerprint of Chrome, Firefox, or Safari:```bash
pip install curl_cffi
```
```python
from curl_cffi import requests as cffi_requests
Impersonates Chrome 124's exact TLS fingerprint, HTTP/2, and headers
resp = cffi_requests.get(
"https://httpbin.org/ip",
proxies={"http": "http://gateway.sparkproxy.io:10000",
"https": "http://gateway.sparkproxy.io:10000"},
impersonate="chrome124",
)
print(resp.json())
```
Available impersonation targets (as of curl_cffi 0.7):
| Impersonation Target | TLS + HTTP Version | Use When |
|---|---|---|
|
chrome124| TLS 1.3, HTTP/2 | General-purpose — matches most desktop Chrome users ||
chrome110| TLS 1.3, HTTP/2 | Sites that specifically detect Chrome 124+ as too new ||
firefox117| TLS 1.3, HTTP/2 | Firefox user demographic ||
safari17_0| TLS 1.3, HTTP/2 | iOS/Mac targets with Safari-heavy traffic ||
edge99| TLS 1.3, HTTP/2 | Corporate or Microsoft-heavy environments |curl_cffialso handles HTTP/2 automatically —requestsonly does HTTP/1.1 by default, which is another detectable mismatch against modern browsers.-
Session-based usage with curl_cffi
```python
from curl_cffi import requests as cffi_requests
session = cffi_requests.Session(impersonate="chrome124")
session.proxies = {
"http": "http://gateway.sparkproxy.io:10000",
"https": "http://gateway.sparkproxy.io:10000",
}
All requests in this session use Chrome's TLS fingerprint
resp = session.get("https://example.com/login")
```
-
-
Set Consistent HTTP Headers {#consistent-headers}
Even when your TLS fingerprint is correct, inconsistent HTTP headers reveal automation. A real Chrome 124 browser always sends a specific set of headers in a specific order. Sending
User-Agent: Chrome/124while omittingsec-ch-uaor sendingAccept: /(Python default) instead of Chrome's real Accept header is a detectable anomaly.Minimum consistent header set for Chrome 124 on Windows:
```python
import requests
CHROME_HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
}
session = requests.Session()
session.headers.update(CHROME_HEADERS)
session.proxies = {"http": "http://gateway.sparkproxy.io:10000",
"https": "http://gateway.sparkproxy.io:10000"}
```
Header order matters. Browsers send headers in a consistent, fixed order. HTTP/2 makes this especially detectable — the HPACK compression encodes header order into the frame.
curl_cffihandles this automatically. With plainrequests, you can userequests.structures.CaseInsensitiveDictonly for storage; the actual wire order may vary by Python version.Combining
curl_cffifor TLS + correct headers is the most reliable approach:```python
from curl_cffi import requests as cffi_requests
resp = cffi_requests.get(
"https://target-site.com",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.google.com/",
},
impersonate="chrome124",
proxies={"http": "http://gateway.sparkproxy.io:10000",
"https": "http://gateway.sparkproxy.io:10000"},
)
```
curl_cffialready sets the correct TLS fingerprint, HTTP/2, and base browser headers for the chosen impersonation target. You only need to add request-specific headers likeReferer.
-
Respect Crawl Rates and robots.txt {#crawl-rate}
Sending 10 requests per second from the same proxy will trigger rate limiting before any fingerprint detection kicks in. Respecting the target site's intended crawl rate is both effective and ethical.
```python
import time
import random
def polite_delay(min_s: float = 1.0, max_s: float = 4.0) -> None:
"""Sleep for a random human-like interval between requests."""
time.sleep(random.uniform(min_s, max_s))
```
Guidelines:
| Crawl Rate | Risk Level | When Appropriate |
|---|---|---|
| > 5 req/s per IP | High — near-certain block | Never |
| 1–5 req/s per IP | Medium | Only with very large proxy pool |
| 1 req / 1–3 s | Low | General scraping |
| 1 req / 5–10 s | Very low | Sensitive sites, e-commerce, login-required |
To check a site's declared crawl rate:
```python
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url("https://example.com/robots.txt")
rp.read()
print(rp.can_fetch("*", "/products")) # True or False
print(rp.crawl_delay("*")) # Returns float or None
```
If
crawl_delayreturns a value, respect it. IgnoringCrawl-delayis one of the most common reasons scraper IPs get added to permanent blocklists.
-
Handle Cookies and Sessions Correctly {#cookies-sessions}
Sites use cookies to track session continuity. Two behaviors trigger blocks:
1. Rotating the proxy but keeping the same cookies. The site sees the same session ID arriving from two different IPs — a signal consistent with proxying. Fix: reset cookies when rotating to a new proxy.
2. Making requests with no cookies at all. Real browsers accumulate cookies progressively — homepage sets a session cookie, subsequent pages send it back. Scripts that skip directly to a product page with no cookies look like bots.
```python
import requests
import random
PROXIES = [
"http://gateway.sparkproxy.io:10000",
"http://gateway.sparkproxy.io:10001",
]
def new_session(proxy_url: str) -> requests.Session:
"""Fresh session (no cookies) bound to one proxy."""
session = requests.Session()
session.proxies = {"http": proxy_url, "https": proxy_url}
return session
def scrape_product(product_url: str) -> str:
proxy = random.choice(PROXIES)
session = new_session(proxy)
Step 1: Hit the homepage to receive initial cookies
session.get("https://example.com/", timeout=10)
Step 2: Now request the target page — cookies are sent automatically
resp = session.get(product_url, timeout=10)
return resp.text
```
Each call to
new_session()creates a session with empty cookies. The homepage visit seeds the session with whatever cookies the site sets on first visit, making subsequent requests look like normal browsing.
-
Avoid Common Bot Detection Signals {#bot-signals}
-
Headless browser detection (Selenium / Playwright)
Selenium sets
navigator.webdriver = truein the browser's JavaScript environment. This is readable by any JavaScript on the page and is the primary detection signal used by Cloudflare and DataDome for browser-based scraping.Selenium fix — undetected-chromedriver:
```bash
pip install undetected-chromedriver
```
```python
import undetected_chromedriver as uc
options = uc.ChromeOptions()
options.add_argument("--proxy-server=gateway.sparkproxy.io:10000")
driver = uc.Chrome(options=options)
driver.get("https://example.com")
```
undetected-chromedriverpatches the Chrome binary to removewebdriverflags and other Selenium-specific modifications.Playwright fix — stealth plugin:
```bash
pip install playwright playwright-stealth
playwright install chromium
```
```python
from playwright.sync_api import sync_playwright
from playwright_stealth import stealth_sync
with sync_playwright() as p:
browser = p.chromium.launch(proxy={
"server": "http://gateway.sparkproxy.io:10000",
})
page = browser.new_page()
stealth_sync(page) # Patches navigator.webdriver and other leaks
page.goto("https://example.com")
browser.close()
```
-
Other bot signals to eliminate
| Signal | What Bots Do | What Real Browsers Do |
|---|---|---|
| Mouse movement | None — direct element click | Random Bezier-curve paths before clicking |
| Viewport size | 800×600 default headless | 1280×800 or 1920×1080 common sizes |
| Timezone | UTC (server default) | Match the proxy's country timezone |
| WebGL renderer | SwiftShader / LLVMpipe (headless default) | Real GPU renderer string |
| Canvas fingerprint | Empty or identical across sessions | Unique noise per session |
For Playwright, set a realistic viewport and timezone:
```python
context = browser.new_context(
viewport={"width": 1280, "height": 800},
locale="en-US",
timezone_id="America/New_York", # Match your proxy's datacenter location
proxy={"server": "http://gateway.sparkproxy.io:10000"},
)
```
-
-
Check for Proxy Header Leaks {#header-leaks}
Some proxies add
X-Forwarded-FororX-Real-IPheaders to outgoing requests, inadvertently revealing your real IP address to the target server. Always verify your proxy does not leak before using it in production.```python
import requests
def check_header_leak(proxy_url: str) -> dict:
proxies = {"http": proxy_url, "https": proxy_url}
resp = requests.get("https://httpbin.org/headers", proxies=proxies, timeout=10)
headers = resp.json().get("headers", {})
leak_headers = {
k: v for k, v in headers.items()
if k.lower() in ("x-forwarded-for", "x-real-ip", "via", "forwarded")
}
return {
"proxy": proxy_url,
"leak_headers": leak_headers,
"has_leak": bool(leak_headers),
}
result = check_header_leak("http://gateway.sparkproxy.io:10000")
print(result)
{"proxy": "...", "leak_headers": {}, "has_leak": False} ← clean proxy
{"proxy": "...", "leak_headers": {"X-Forwarded-For": "203.0.113.1"}, "has_leak": True} ← leaks real IP
```
If
has_leakisTrue, switch to a proxy that strips these headers. SparkProxy datacenter proxies do not forward client IP headers.
-
Test Whether You Are Being Detected {#detection-test}
Before deploying, test your setup against detection services:
```python
from curl_cffi import requests as cffi_requests
def detection_test(proxy_url: str) -> None:
proxies = {"http": proxy_url, "https": proxy_url}
session = cffi_requests.Session(impersonate="chrome124")
session.proxies = proxies
tests = {
"Exit IP": "https://httpbin.org/ip",
"Headers": "https://httpbin.org/headers",
"Cloudflare check": "https://www.cloudflare.com/cdn-cgi/trace",
}
for name, url in tests.items():
try:
resp = session.get(url, timeout=10)
if name == "Cloudflare check":
Parse key=value text response
data = dict(line.split("=", 1) for line in resp.text.strip().splitlines() if "=" in line)
print(f"[Cloudflare] ip={data.get('ip')} uag={data.get('uag', '')[:40]}")
else:
print(f"[{name}] {resp.status_code}: {resp.text[:120]}")
except Exception as exc:
print(f"[{name}] FAILED: {exc}")
detection_test("http://gateway.sparkproxy.io:10000")
```
https://www.cloudflare.com/cdn-cgi/tracereturns the IP Cloudflare sees, the User-Agent string it received, and whether it thinks the request is from a bot. Ifuagmatches yourUser-Agentheader andipmatches the proxy IP, the request looks legitimate to Cloudflare.
-
Common Blocking Patterns and How to Respond {#blocking-patterns}
| Block Pattern | How to Identify | Fix |
|---|---|---|
| Immediate 403 on every request | IP in blocklist; or TLS fingerprint flagged instantly | Switch proxy; switch to curl_cffi with browser impersonation |
| 403 after N requests | Rate limit hit | Slow down; rotate proxy per request; add delays |
| CAPTCHA (JavaScript challenge) | Cloudflare "Checking your browser" page | Use curl_cffi; or switch to headless browser with stealth |
| Soft block: returns empty results | Anti-scraping at application layer (not HTTP) | Check session/cookie handling; simulate homepage visit first |
| 407 Proxy Authentication Required | Proxy credentials wrong or expired | Verify credentials in SparkProxy dashboard |
| Block only on HTTPS | CONNECT tunneling disabled; or TLS fingerprint mismatch | Switch to proxy with CONNECT support; use curl_cffi |
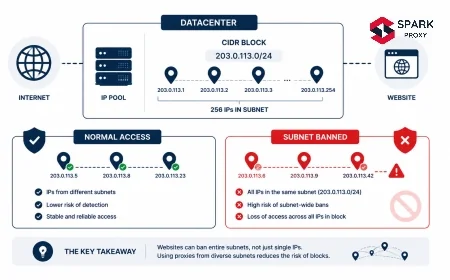
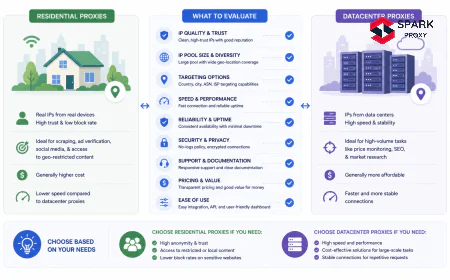
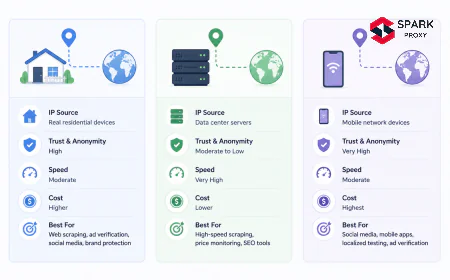
| Works from laptop, blocked from cloud | Cloud provider ASN flagged (AWS, GCP, Azure ranges known) | Use residential or mobile proxies instead of datacenter |
datacenter vs residential proxies
-
About the Author
SparkProxy Technical Team — The SparkProxy engineering team builds and maintains global datacenter and residential proxy infrastructure. This guide reflects anti-detection patterns validated with Python 3.11+, curl_cffi 0.7+, playwright-stealth 0.1.3+, and undetected-chromedriver 3.5+ (May 2026).
Citations: curl_cffi — Browser TLS impersonation for Python · Playwright Stealth — playwright-stealth on PyPI