




Using Datacenter Proxies for Web Scraping
Use datacenter proxies for web scraping: set up proxy pools, rotate IPs, scrape at scale with Python requests and Scrapy, and handle rate limits and bans.

Table of Contents
- Why Use Datacenter Proxies for Web Scraping? {#why-datacenter}
- Scraping Use Cases: Where Datacenter Proxies Fit {#scraping-use-cases}
- Set Up a Datacenter Proxy Pool in Python {#proxy-pool-setup}
- Single-Domain Scraping with Session Management {#single-domain}
- Multi-Domain Scraping with Per-Domain Rotation {#multi-domain}
- Scrapy Integration: Datacenter Proxy Middleware {#scrapy-integration}
- Handle Rate Limits and 429 Responses {#rate-limits}
- Scale to Millions of Pages {#scale}
- Datacenter vs Residential Proxies for Scraping {#datacenter-vs-residential}
- Common Scraping Errors and Fixes {#common-errors}
- About the Author
-
Why Use Datacenter Proxies for Web Scraping? {#why-datacenter}
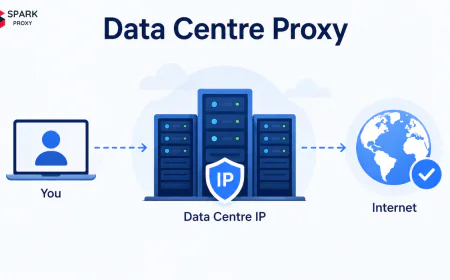
Datacenter proxies are the practical default for most web scraping workloads. They are faster, cheaper, and more available than residential proxies — but they require more deliberate configuration to avoid bans. A datacenter IP that sends 50 requests per second to a single domain with no session handling and a Python User-Agent will be blocked within minutes. The same datacenter IP, configured with proper rotation, realistic headers, and a controlled crawl rate, can scrape millions of pages per day. This guide covers every data extraction proxy pattern you need: pool setup, rotation, session management, Scrapy integration, and how to match the right proxy to the scraping use case.
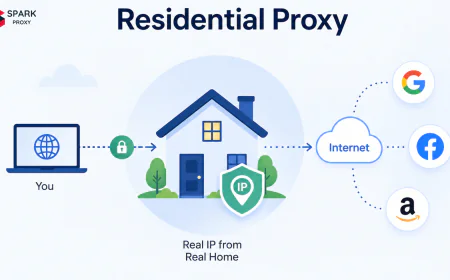
Datacenter proxies are IP addresses hosted in commercial data centers — not assigned to residential internet service subscribers. For web scraping, they offer three advantages over making requests from a single server IP:
| Advantage | Detail |
|---|---|
| IP diversity | Spread requests across dozens or hundreds of IPs to stay below per-IP rate limits |
| Speed | Datacenter connections typically deliver 100–500 Mbps with < 50 ms intra-region latency |
| Cost | Significantly cheaper per GB and per IP than residential proxies |
| Availability | Large proxy pools with consistent uptime — no dependency on residential device online status |
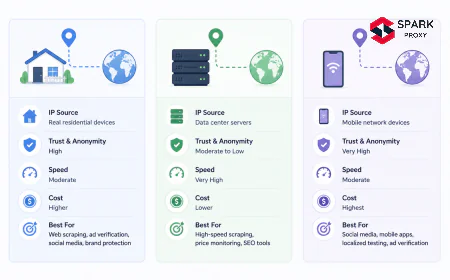
The tradeoff is detectability: datacenter IP ranges are well-known (AWS, GCP, Azure, and proxy providers' ASNs are in public databases). Sites that specifically target scraper-blocking will flag datacenter ASNs. For those cases, residential or ISP proxies are better. For everything else — price monitoring, public data collection, SEO research, ad verification — datacenter proxies are the right tool.
-
Scraping Use Cases: Where Datacenter Proxies Fit {#scraping-use-cases}
Different scraping use cases demand different proxy behaviors. Datacenter proxies are optimal for:
| Use Case | Why Datacenter Proxy Is the Right Choice |
|---|---|
| Price monitoring (e-commerce) | High-volume, repeated requests to the same domain; speed matters; IP diversity prevents rate-limit bans |
| SERP scraping (search results) | Google and Bing rate-limit by IP aggressively; datacenter pool with rotation covers this well |
| Public data aggregation (news, weather, sports) | Low bot protection; datacenter speed and low cost are the priority |
| SEO rank tracking | Geo-specific datacenter IPs provide accurate local SERPs without residential cost |
| Real estate listings | High page count, moderate bot protection; datacenter handles volume |
| Job board aggregation | Public listings with moderate rate limits; datacenter rotation handles it cleanly |
| Ad verification | Verify ad delivery from specific geos; datacenter IPs with geo-targeting |
Use cases where datacenter proxies are not the first choice:
| Use Case | Better Proxy Type | Reason |
|---|---|---|
| Social media scraping | Residential / ISP | Platforms block known datacenter ASNs by default |
| Account creation / management | Residential | Platforms flag datacenter IPs for account-related actions |
| Highly bot-protected e-commerce (luxury, tickets) | Residential | Aggressive Cloudflare/Akamai rules target datacenter ranges |
-
Set Up a Datacenter Proxy Pool in Python {#proxy-pool-setup}
A data extraction proxy pool for Python needs three things: a list of working proxies, a rotation mechanism, and retry logic for failures. Here is a production-ready pattern:
```python
import random
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
Your SparkProxy datacenter proxy list
PROXY_POOL = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
Add as many as your plan allows
]
Consistent browser headers to avoid header-based detection
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def make_session(proxy_url: str) -> requests.Session:
retry = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry)
session = requests.Session()
session.mount("http://", adapter)
session.mount("https://", adapter)
session.proxies = {"http": proxy_url, "https": proxy_url}
session.headers.update(HEADERS)
session.trust_env = False # Prevent OS env vars from overriding proxy
return session
def scrape(url: str) -> requests.Response | None:
proxy = random.choice(PROXY_POOL)
session = make_session(proxy)
try:
resp = session.get(url, timeout=15)
resp.raise_for_status()
return resp
except requests.exceptions.RequestException:
return None
```
Key configuration details:
trust_env = False— preventsHTTP_PROXY/HTTPS_PROXYenvironment variables from silently overriding the configured proxystatus_forcelist=[429, ...]— retries on rate-limit and server error responses automatically- New session per request — ensures cookies do not accumulate across different proxy IPs
-
Single-Domain Scraping with Session Management {#single-domain}
For scraping a single domain at high volume, the most effective web scraping datacenter proxy pattern is to assign one proxy per logical scraping "session" (a page tree or a user flow), not per request. This prevents the site from seeing the same session cookie arrive from five different IPs — a strong bot signal.
```python
import time
import random
import requests
from dataclasses import dataclass, field
PROXY_POOL = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
]
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
}
@dataclass
class ProxyScraper:
proxy_url: str
session: requests.Session = field(default_factory=requests.Session)
def __post_init__(self):
self.session.proxies = {"http": self.proxy_url, "https": self.proxy_url}
self.session.headers.update(HEADERS)
self.session.trust_env = False
def warm_up(self, homepage: str) -> None:
"""Visit the homepage first to receive initial cookies."""
self.session.get(homepage, timeout=10)
time.sleep(random.uniform(0.5, 1.5))
def get(self, url: str) -> requests.Response:
time.sleep(random.uniform(1.0, 3.0))
return self.session.get(url, timeout=15)
def scrape_product_category(base_url: str, page_urls: list[str]) -> list[str]:
"""Scrape a list of pages using one proxy per batch."""
results = []
scraper = ProxyScraper(proxy_url=random.choice(PROXY_POOL))
scraper.warm_up(base_url) # Seed session cookies
for url in page_urls:
resp = scraper.get(url)
if resp.status_code == 200:
results.append(resp.text)
elif resp.status_code == 429:
Rate limited — rotate to a new proxy and continue
scraper = ProxyScraper(proxy_url=random.choice(PROXY_POOL))
scraper.warm_up(base_url)
return results
```
The
warm_up()call visits the homepage first, which:- Sets session cookies as a real browser would receive them
- Establishes the
Refererheader chain for subsequent requests - Prevents "cold start" signals from a direct deep-page hit
-
Multi-Domain Scraping with Per-Domain Rotation {#multi-domain}
When scraping multiple domains simultaneously, isolate proxy assignment per domain. Using the same proxy across unrelated domains does not typically cause blocks, but it wastes rotation capacity and makes debugging harder.
```python
import random
import requests
from collections import defaultdict
PROXY_POOL = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
"http://your-proxy-4.sparkproxy.com:10003",
]
Assign a fixed proxy to each domain for the duration of the run
_domain_proxy: dict[str, str] = {}
def get_proxy_for_domain(domain: str) -> str:
if domain not in _domain_proxy:
_domain_proxy[domain] = random.choice(PROXY_POOL)
return _domain_proxy[domain]
def scrape_url(url: str) -> str | None:
domain = url.split("/")[2]
proxy = get_proxy_for_domain(domain)
session = requests.Session()
session.proxies = {"http": proxy, "https": proxy}
session.trust_env = False
try:
resp = session.get(url, timeout=15)
return resp.text if resp.ok else None
except requests.exceptions.RequestException:
return None
urls = [
"https://site-a.com/products/1",
"https://site-b.com/listings/2",
"https://site-a.com/products/3", # Same proxy as first site-a.com request
]
for url in urls:
result = scrape_url(url)
print(f"{url}: {'OK' if result else 'FAILED'}")
```
For large-scale concurrent multi-domain scraping, replace the dict with a thread-safe
threading.Lock-protected structure orqueue.Queueper domain.
-
Scrapy Integration: Datacenter Proxy Middleware {#scrapy-integration}
Scrapy has a built-in
HttpProxyMiddlewarethat readsrequest.meta["proxy"]. A custom downloader middleware assigns a rotating datacenter proxy to every outgoing request:myproject/middlewares.py:```python
import random
import logging
logger = logging.getLogger(__name__)
class DatacenterProxyMiddleware:
"""Assigns a random SparkProxy datacenter proxy to every Scrapy request."""
PROXIES = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
]
def process_request(self, request, spider):
proxy = random.choice(self.PROXIES)
request.meta["proxy"] = proxy
logger.debug(f"Assigned proxy {proxy} to {request.url}")
def process_response(self, request, response, spider):
if response.status == 429:
Force a retry with a different proxy
logger.warning(f"429 on {request.url} — rotating proxy")
request.meta["proxy"] = random.choice(self.PROXIES)
return request # Retry the request
return response
def process_exception(self, request, exception, spider):
logger.error(f"Proxy error on {request.url}: {exception}")
request.meta["proxy"] = random.choice(self.PROXIES)
return request # Retry with a new proxy
```
myproject/settings.py:```python
DOWNLOADER_MIDDLEWARES = {
"myproject.middlewares.DatacenterProxyMiddleware": 100,
"scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware": 110,
Optionally add retry middleware
"scrapy.downloadermiddlewares.retry.RetryMiddleware": 550,
}
RETRY_TIMES = 3
RETRY_HTTP_CODES = [429, 500, 502, 503, 504]
Polite crawl settings
DOWNLOAD_DELAY = 1.5 # Seconds between requests per domain
RANDOMIZE_DOWNLOAD_DELAY = True # Vary between 0.5× and 1.5× of DOWNLOAD_DELAY
CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 4
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
}
```
The
process_responsehandler catches 429s and immediately retries with a fresh proxy — this is more responsive than relying solely on Scrapy's built-inRetryMiddleware, which does not rotate proxies on retry.
-
Handle Rate Limits and 429 Responses {#rate-limits}
Rate limits are the most common block type for web scraping datacenter proxy setups. The correct response to a 429 is: back off, rotate to a new proxy, and retry — not just retry with the same proxy.
```python
import time
import random
import requests
PROXY_POOL = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
]
def scrape_with_backoff(
url: str,
max_retries: int = 5,
base_delay: float = 2.0,
) -> requests.Response | None:
tried_proxies: set[str] = set()
for attempt in range(max_retries):
Pick a proxy not yet used this retry cycle
available = [p for p in PROXY_POOL if p not in tried_proxies]
if not available:
tried_proxies.clear() # Reset if we've cycled through all
available = PROXY_POOL
proxy = random.choice(available)
tried_proxies.add(proxy)
session = requests.Session()
session.proxies = {"http": proxy, "https": proxy}
session.trust_env = False
try:
resp = session.get(url, timeout=15)
if resp.status_code == 429:
retry_after = int(resp.headers.get("Retry-After", base_delay * (2 ** attempt)))
wait = min(retry_after, 60) # Cap at 60 seconds
time.sleep(wait)
continue
if resp.status_code == 200:
return resp
except requests.exceptions.RequestException:
time.sleep(base_delay * (2 ** attempt))
return None
```
The
Retry-Afterheader, when present, tells you exactly how long to wait. Respecting it avoids accumulating additional strikes against the IP.
-
Scale to Millions of Pages {#scale}
Scraping at scale requires moving beyond single-threaded sequential requests. Three patterns for high-throughput data extraction proxy usage:
-
ThreadPoolExecutor (I/O-bound, simple)
```python
import concurrent.futures
import random
import requests
PROXY_POOL = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
]
def fetch(url: str) -> tuple[str, int]:
proxy = random.choice(PROXY_POOL)
try:
r = requests.get(
url,
proxies={"http": proxy, "https": proxy},
timeout=15,
)
return url, r.status_code
except Exception:
return url, 0
URLS = [f"https://example.com/product/{i}" for i in range(10_000)]
with concurrent.futures.ThreadPoolExecutor(max_workers=50) as executor:
for url, status in executor.map(fetch, URLS):
if status != 200:
print(f"FAILED: {url} ({status})")
```
-
Async httpx (high-concurrency, event loop)
```python
import asyncio
import random
import httpx
PROXIES = [
"http://your-proxy-1.sparkproxy.com:10000",
"http://your-proxy-2.sparkproxy.com:10001",
"http://your-proxy-3.sparkproxy.com:10002",
]
async def fetch(url: str) -> tuple[str, int]:
proxy = random.choice(PROXIES)
async with httpx.AsyncClient(proxy=proxy, timeout=15) as client:
try:
resp = await client.get(url)
return url, resp.status_code
except Exception:
return url, 0
async def main(urls: list[str], concurrency: int = 100):
semaphore = asyncio.Semaphore(concurrency)
async def bounded_fetch(url: str):
async with semaphore:
return await fetch(url)
tasks = [bounded_fetch(url) for url in urls]
return await asyncio.gather(*tasks)
urls = [f"https://example.com/product/{i}" for i in range(10_000)]
results = asyncio.run(main(urls, concurrency=100))
```
-
Throughput estimates by approach
| Method | Proxies | Requests/min | Best For |
|---|---|---|---|
| Single-threaded | 1 | ~60–120 | Development / testing |
| ThreadPoolExecutor | 10 | ~600–1,200 | Small to medium jobs |
| ThreadPoolExecutor | 50 | ~3,000–6,000 | Production scraping |
| async httpx | 50 | ~6,000–15,000 | High-concurrency, I/O-heavy |
| Scrapy + middleware | 50 | ~5,000–12,000 | Structured crawling, pipelines |
Actual throughput depends on target site response time and proxy latency. Add a
Semaphore(async) or limitmax_workers(threads) to avoid overwhelming either the proxy pool or the target site.
-
-
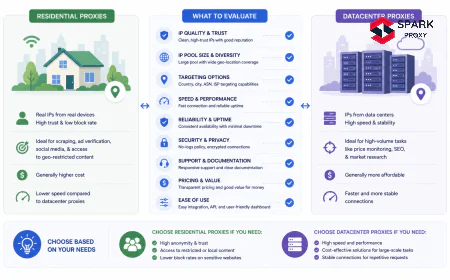
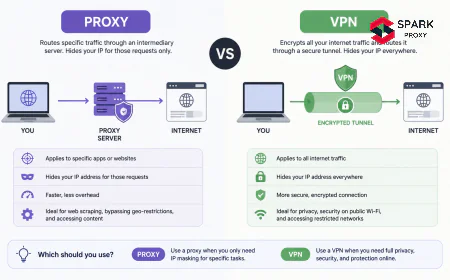
Datacenter vs Residential Proxies for Scraping {#datacenter-vs-residential}
Choosing the right proxy type for your scraping use case is a cost-vs-detection tradeoff:
| Factor | Datacenter Proxy | Residential Proxy |
|---|---|---|
| Cost | Low (typically $0.5–3/GB) | High (typically $5–15/GB) |
| Speed | Fast (< 50 ms intra-region) | Slower (100–300 ms typical) |
| IP reputation | Known datacenter ASN — easier to detect | Real ISP IPs — harder to detect |
| Pool size | Large, always available | Depends on active residential devices |
| Best for | High-volume public data, SEO, price monitoring | Social media, login-required, Ticketmaster-level protection |
| Geo-targeting | Country, region, ASN | Country, city, ISP, carrier |
The practical rule: start with datacenter proxies and only upgrade to residential if the target site specifically blocks datacenter ASNs. Most public websites do not apply datacenter-specific blocks.
-
Common Scraping Errors and Fixes {#common-errors}
| Error / Symptom | Cause | Fix |
|---|---|---|
|
403 Forbiddenimmediately | IP blocklisted or TLS fingerprint flagged | Rotate to a fresh proxy; switch tocurl_cffifor TLS matching ||
429 Too Many Requests| Request rate too high for the IP | Add delays; reducemax_workers; rotate proxy on retry ||
407 Proxy Authentication Required| Wrong credentials or IP not whitelisted | Check proxy credentials in SparkProxy dashboard ||
ProxyError: Cannot connect to proxy| Proxy host down or port blocked | Run health check before job start; switch to a known-good proxy || Scrape returns empty content | JavaScript-rendered page (SPA) | Switch to Playwright or Selenium; or find the underlying API the SPA calls |
| Real IP shown in scraped data |
trust_env = Falsenot set; env var overriding proxy | Addsession.trust_env = False|| Works on 100 pages, fails on 1,000 | Session cookie accumulation flagging the session | Create a new session (new proxy) every N pages or after each login flow |
| Scrapy ignores custom proxy middleware | Priority order wrong | Set custom middleware to 100,
HttpProxyMiddlewareto 110 (custom must run first) |
-
About the Author
SparkProxy Technical Team — The SparkProxy engineering team builds and maintains global datacenter and residential proxy infrastructure. This guide reflects scraping patterns validated with Python 3.11+, requests 2.32+, httpx 0.27+, Scrapy 2.12+, and Playwright 1.44+ (May 2026).
Citations: Scrapy documentation — Downloader Middleware · httpx documentation — Async support