




Using Proxies for Academic Research Data Collection: Guide
Over 7.5 million academic papers are published annually. Learn how an academic research proxy enables large-scale dataset collection, bibliometric analysis, and research data aggregation without rate limit blocks.
Table of Contents
- Why Academic Researchers Need Proxy Infrastructure
- What Is an Academic Research Proxy?
- What Data Do Researchers Collect Using Proxies?
- How to Configure Proxies for Research Data Collection
- Which Academic Data Sources Work with Datacenter Proxies?
- What Are the Ethical and Legal Considerations?
- Conclusion
-
Why Academic Researchers Need Proxy Infrastructure
Using Proxies for Academic Research Data Collection: Guide
More than 7.5 million academic papers are published every year (STM Association, 2023). PubMed alone indexes over 35 million citations. arXiv carries more than 2.3 million preprints across physics, mathematics, computer science, and adjacent fields. The full-text content of this literature, along with citation networks, author metadata, publication timelines, and funding information, forms the raw material for computational research in natural language processing, bibliometrics, science of science, and computational social science.
The problem for researchers who want to collect this data programmatically is not access — most academic databases explicitly permit machine access under their terms. The problem is infrastructure. Publisher platforms, preprint servers, and database interfaces impose per-IP rate limits to manage server load, and research institutions running collection jobs from shared IP ranges hit those limits almost immediately. A research server at a university might share its outbound IP with dozens of other automated jobs across departments. A single collection run that makes 1,000 API calls can exhaust the rate allowance for the entire institution's IP block within minutes.
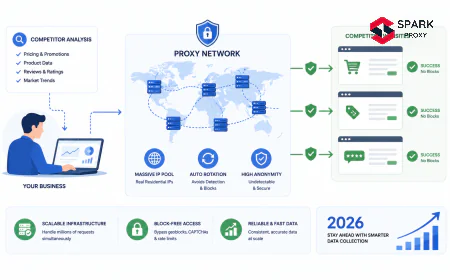
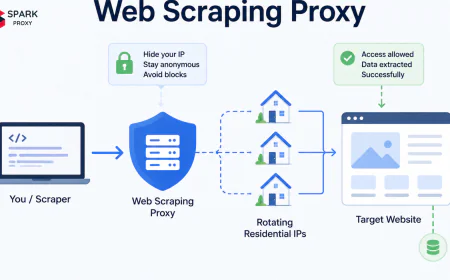
An academic research proxy routes collection requests through rotating IPs so that per-IP rate limits don't terminate collection jobs mid-run, geographic access restrictions don't create coverage gaps, and institutional IP blocks don't propagate to downstream databases. This guide covers the use cases, configuration, source compatibility, and ethical framework for proxy-based academic data collection.
Key Takeaways
- Over 7.5 million academic papers are published annually (STM Association, 2023) — large-scale collection requires proxy infrastructure to stay within per-source rate limits
- PubMed's official rate limit is 10 requests/second without API key, 10 requests/second with key — shared institutional IPs exhaust this in seconds across concurrent jobs
- The global research data management market is valued at $1.2 billion and growing at 19% CAGR (MarketsandMarkets, 2024) — infrastructure investment follows data volume
- Most major academic data sources (PubMed, arXiv, CrossRef, CORE) explicitly permit programmatic access with stated rate limits — proxy infrastructure makes those limits usable at research scale
Computational research at scale requires data collection infrastructure that most research institutions are not architected to support. The problem has three layers:
Shared outbound IP addresses: Universities and research institutions route outbound traffic through shared IP pools or NAT gateways. A computer science lab running a corpus collection job, a sociology department running a social media collection pipeline, and a library's automated cataloging system may all appear on the public internet as the same IP address or small IP range. When one of these jobs hits a rate limit, the database or API provider rate-limits the IP — which affects all concurrent and subsequent requests from the entire institution's network. A single aggressive collection run can inadvertently block all programmatic access from an institution for hours.
Rate limits that assume single-user access: Most academic database rate limits are designed for individual researcher access, not institutional-scale collection. CrossRef's polite pool allows 50 requests/second for registered users — generous for a single researcher, but a 5-million-DOI corpus traversal at 50 req/sec takes 27 hours from a single registered IP. PubMed's NCBI E-utilities API allows 10 requests/second with an API key, which sounds fast until you're collecting 35 million records with metadata.
Geographic access controls on regional data: Some academic databases, government research repositories, and national library systems apply geographic access controls. European open-access repositories, national statistical offices, and some regional journal platforms restrict access to IP ranges associated with institutions in their jurisdiction. Research requiring cross-national data coverage requires proxy IPs in the relevant regions.
What we've found: The most common proxy use case in academic research isn't circumventing paywalls — it's distributing load across IPs to comply with per-IP rate limits while completing collection jobs within a reasonable timeframe. A researcher building a 10-million-paper NLP training corpus from PubMed Central's Open Access subset can do so within the explicit terms of PMC's bulk data access policy; the proxy infrastructure just makes the timeline practical (hours vs. weeks from a single IP). The access is permitted; the proxy makes it feasible.
-
What Is an Academic Research Proxy?
An academic research proxy is a proxy server used to route automated scholarly data collection requests through rotating IP addresses. It provides the network layer between a research collection pipeline and academic data sources — databases, APIs, preprint servers, publisher portals — distributing request volume so per-IP rate limits don't terminate multi-day collection jobs.
In a research context, proxy infrastructure serves three distinct functions:
Rate distribution across IP pool: Spreading API calls and web requests across multiple IPs so that each IP's request rate stays within the rate limits published by the data source. For a 10-req/sec API limit, 10 IPs rotating in round-robin each make 1 request/sec — well within the individual limit, with 10x aggregate throughput.
Job isolation between research projects: Assigning separate proxy pools or IP subsets to different collection projects prevents one project's rate limit violations from affecting another. A lab running simultaneous corpus collection jobs for three separate grants benefits from IP-level project isolation.
Geographic coverage for regional sources: Routing requests through IPs in the relevant country or region for data sources that apply geographic access controls, ensuring complete coverage of regional academic databases without institutional geo-restriction.
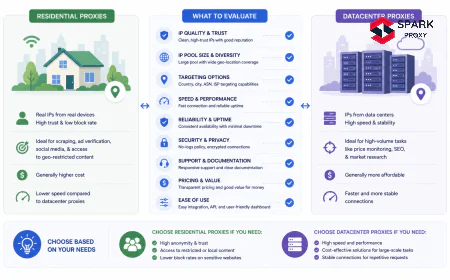
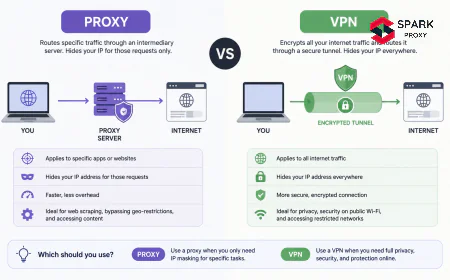
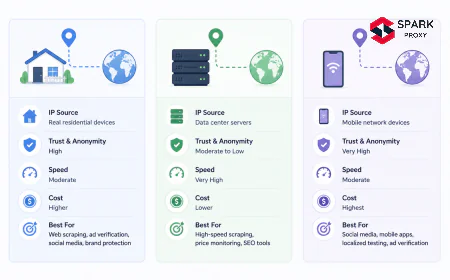
datacenter vs residential proxies
-
What Data Do Researchers Collect Using Proxies?
Academic data collection spans a wide range of source types and research applications. The workloads break down by data category and downstream research use:
Full-text paper corpora: Bulk collection of research papers, preprints, and technical reports from PubMed Central Open Access, arXiv, SSRN, CORE, Semantic Scholar, and other open-access repositories. Used for NLP model training, topic modeling, citation analysis, and science-of-science research. arXiv alone adds approximately 20,000 new preprints per month — continuous corpus maintenance requires recurring collection runs.
Citation and reference networks: DOI-level citation data from CrossRef, OpenCitations, and Semantic Scholar APIs. Used to construct academic knowledge graphs, measure research impact, identify influential papers, and study the diffusion of ideas across disciplines. CrossRef's API provides metadata for over 150 million DOIs — traversal at scale requires rotating IP infrastructure to stay within rate limits.
Author and affiliation data: Researcher profiles, institutional affiliations, ORCID identifiers, and publication histories from OpenAlex, ORCID public data, and institutional repository APIs. Used for researcher career trajectory analysis, collaboration network mapping, and gender/diversity research in academia.
Web content for social science research: News articles, social media archives, political speech archives, government records, and public discourse data for computational social science and political science research. This category involves the broadest range of sources and often requires JavaScript rendering alongside proxy rotation.
Dataset and code availability tracking: Tracking data sharing and code availability statements in published papers, repository links on GitHub, Zenodo, and Figshare, and software citations. Used by open science researchers studying replication practices and research transparency trends.
Conference and preprint metadata: Paper submission data, acceptance rates, reviewer assignments (where public), and presentation records from conference management systems and preprint server APIs. Used for studying peer review patterns and publication bias.
Source: STM Association, 2023; MarketsandMarkets, 2024. Adoption rates among computational researchers using proxy-assisted automated collection by academic data category.
-
How to Configure Proxies for Research Data Collection
Academic data collection has configuration requirements that differ from commercial web data workloads. The priority hierarchy is different: data completeness and accuracy matter more than collection speed, most sources have published rate limits (rather than undocumented thresholds), and the ethical obligation to be a polite API citizen is higher in research contexts than in commercial ones.
-
Respecting Rate Limits and Polite Access Patterns
The correct mental model for proxy use in academic research is not "evading rate limits" — it's "distributing your legitimate aggregate throughput across multiple IPs so that per-IP rate limits accommodate your total collection volume." Most academic data sources publish their rate limits and explicitly permit programmatic access. Proxy infrastructure makes those rate limits work at research scale.
A production academic corpus collector with per-source rate configuration, polite headers, and retry logic:
```python
import requests
import time
import random
import logging
from datetime import datetime, timedelta
from typing import Optional
from dataclasses import dataclass, field
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
@dataclass
class SourceConfig:
"""Per-source rate limit and access configuration for academic APIs."""
base_url: str
req_per_second: float # Stay at 80% of published limit for safety margin
contact_email: str # Used in User-Agent for polite pool access
api_key: Optional[str] = None
requires_key_header: bool = False
Configuration for major academic data sources
SOURCE_CONFIGS = {
"pubmed": SourceConfig(
base_url="https://eutils.ncbi.nlm.nih.gov/entrez/eutils/",
req_per_second=8.0, # Published limit: 10/sec with API key; use 80%
contact_email="[email protected]",
api_key="YOUR_NCBI_API_KEY",
),
"crossref": SourceConfig(
base_url="https://api.crossref.org/",
req_per_second=40.0, # Polite pool: 50/sec; use 80%
contact_email="[email protected]",
),
"arxiv": SourceConfig(
base_url="https://export.arxiv.org/api/",
req_per_second=2.0, # arXiv asks for 3-second delays; 2/sec is conservative
contact_email="[email protected]",
),
"openalex": SourceConfig(
base_url="https://api.openalex.org/",
req_per_second=8.0, # Published limit: 10/sec with polite pool
contact_email="[email protected]",
),
}
PROXY_POOL = [
"http://user:pass@dc-proxy1:port",
"http://user:pass@dc-proxy2:port",
"http://user:pass@dc-proxy3:port",
Pool size: (target_req_per_second / safe_req_per_ip_per_second) IPs
For CrossRef at 40 req/sec with 5 req/ip/sec safe rate: ~8 IPs minimum
]
ip_last_used: dict[str, datetime] = {}
MIN_IP_INTERVAL = 1.0 # Minimum seconds between reuses of any single IP
def build_headers(config: SourceConfig) -> dict:
"""
Build polite request headers identifying the research project.
Academic APIs use the User-Agent and mailto parameter for polite pool routing.
"""
headers = {
"User-Agent": f"ResearchCollector/1.0 (mailto:{config.contact_email})",
"Accept": "application/json",
}
if config.requires_key_header and config.api_key:
headers["Authorization"] = f"Bearer {config.api_key}"
return headers
def get_proxy() -> Optional[str]:
"""Return an available proxy IP respecting minimum reuse interval."""
now = datetime.now()
available = [
p for p in PROXY_POOL
if (now - ip_last_used.get(p, datetime.min)).total_seconds() >= MIN_IP_INTERVAL
]
return random.choice(available) if available else None
def fetch_academic(url: str, source_key: str, params: dict = None) -> Optional[dict]:
"""
Fetch academic API data with polite rate limiting and proxy rotation.
Enforces per-source rate limits and provides structured retry with backoff.
"""
config = SOURCE_CONFIGS[source_key]
min_interval = 1.0 / config.req_per_second
headers = build_headers(config)
Add API key as query param where required (e.g., NCBI)
if params is None:
params = {}
if config.api_key and not config.requires_key_header:
params["api_key"] = config.api_key
for attempt in range(3):
proxy = get_proxy()
if proxy:
ip_last_used[proxy] = datetime.now()
proxies = {"http": proxy, "https": proxy} if proxy else None
try:
resp = requests.get(
url, params=params, headers=headers,
proxies=proxies, timeout=30,
)
if resp.status_code == 200:
return resp.json()
if resp.status_code == 429:
retry_after = int(resp.headers.get("Retry-After", 60))
logging.warning(f"Rate limited by {source_key} — waiting {retry_after}s")
time.sleep(retry_after)
continue
logging.warning(f"{source_key} returned {resp.status_code} for {url}")
except requests.RequestException as e:
logging.error(f"Request error for {source_key}: {e}")
time.sleep(min_interval * (2 ** attempt)) # Exponential backoff on failure
return None
Example: collect metadata for a set of DOIs via CrossRef
DOIS = [
"10.1038/s41586-021-03819-2",
"10.1126/science.abm4003",
"10.1145/3442188.3445922",
]
for doi in DOIS:
url = f"https://api.crossref.org/works/{doi}"
result = fetch_academic(url, "crossref")
if result:
title = result.get("message", {}).get("title", ["[no title]"])[0]
logging.info(f"Collected: {title[:60]}")
time.sleep(1.0 / SOURCE_CONFIGS["crossref"].req_per_second)
```
Key configuration decisions for academic data collection:
Always include a contact email in the User-Agent: CrossRef, OpenAlex, and several other academic APIs route requests with a
mailto:identifier in the User-Agent to a dedicated "polite pool" with higher rate limits and better availability. This is not just good practice — it is the documented mechanism for accessing the higher-tier service level. Omitting it means your requests go to the shared pool with lower limits.Configure per-source rate limits explicitly: Different academic data sources have different limits that differ by API key tier, registered use, and endpoint. Hard-code each source's limit in a configuration object and enforce it in code rather than using a single global rate. CrossRef allows 40+ req/sec in the polite pool; arXiv requests 3-second delays. Treating them the same wastes CrossRef capacity and violates arXiv's access guidelines.
Use exponential backoff on 429 responses, not simple retry: Academic API servers are shared infrastructure. A 429 means the server is asking you to back off — respecting
Retry-Afterheaders and implementing exponential backoff on subsequent 429s is both correct behavior and more effective than immediate retry.how to rotate proxies in python
-
-
Which Academic Data Sources Work with Datacenter Proxies?
Source: Published API documentation for each platform, 2025-2026. Rate limits vary by registration status and API key tier. Publisher TDM APIs require institutional licensing. What we've found: Google Scholar is the first source most researchers think of for citation data — and the worst option for programmatic collection. Google Scholar has no official API, actively blocks automated access, and applies aggressive IP-based blocks. The correct alternative is Semantic Scholar (100 req/sec with API key, research use explicitly permitted, 200+ million papers indexed) or OpenAlex (full open-access, 10 req/sec in polite pool, complete coverage of academic literature with OA status flags). Both provide better machine-readable data than Scholar's web interface, with documented rate limits and explicit research use permissions. Teams investing collection infrastructure in Scholar are solving the wrong problem.
Proxy pool sizing for academic data workloads:
| Dataset Target | Source | Requests Needed | Pool Size | Collection Time |
|---|---|---|---|---|
| 1M paper metadata | CrossRef API | 1M requests | 4-6 IPs | ~7 hours at 40 req/sec |
| 10M paper metadata | OpenAlex API | 10M requests | 6-10 IPs | ~14 hours at 10 req/sec (paginated) |
| 35M PubMed citations | NCBI E-utilities | 35M requests | 8-12 IPs | ~50 hours at 10 req/sec |
| arXiv full corpus | arXiv API (bulk) | Use bulk S3 data | N/A — use S3 export | Hours (S3 preferred) |
| 500K DOI metadata | CrossRef (polite) | 500K requests | 2-4 IPs | ~3.5 hours at 40 req/sec |
-
What Are the Ethical and Legal Considerations?
Academic data collection with proxies operates under a clearer ethical and legal framework than commercial web data collection, because most academic data sources are specifically designed for programmatic research access. The framework has distinct layers:
Sources with explicit bulk access permissions: PubMed Central's Open Access subset, arXiv, CrossRef, OpenAlex, and CORE all explicitly document and permit bulk programmatic access in their access policies. NCBI (PubMed) provides a dedicated bulk download pathway via FTP/S3 for researchers who need full corpus access. Using proxy infrastructure to stay within per-IP rate limits while accessing these sources is straightforwardly within the terms of use — you are accessing permitted data within documented technical constraints.
Text and data mining (TDM) rights for licensed content: In the EU, the Copyright in the Digital Single Market Directive (Article 4) establishes a mandatory exception permitting text and data mining of lawfully accessed content for research purposes. In the US, fair use analysis generally supports non-commercial research TDM. Major publishers (Elsevier, Springer, Wiley) operate dedicated TDM APIs for institutional subscribers, providing structured programmatic access to licensed content without requiring web scraping.
The difference between rate distribution and circumvention: Using proxies to distribute legitimate aggregate throughput across IPs — staying within each source's rate limits while achieving research-scale collection — is different from using proxies to circumvent access controls. The former respects the source's technical infrastructure; the latter doesn't. The ethical line tracks the technical distinction: staying within published rate limits via IP distribution is polite access at scale; exceeding them or bypassing authentication is not.
Human subjects research and IRB scope: If collected data includes information about identifiable individuals — author publication records, research career data, collaborative network data — IRB (Institutional Review Board) review may apply depending on research institution policy and funding source requirements. Pure bibliometric data (publication counts, citation networks, funding acknowledgments) typically falls outside human subjects research definitions. Consult your institution's IRB guidance for data involving individual researcher identification.
Data sharing and reproducibility obligations: Research using collected academic datasets is increasingly subject to data availability requirements from journals and funders. If the collected dataset is derived from sources with usage restrictions (publisher TDM APIs, licensed databases), downstream data sharing may be limited. Datasets derived from fully open sources (PubMed OA, arXiv, OpenAlex) can typically be shared and published without restriction.
Reliable Proxy Infrastructure for Research Data Collection
SparkProxy's datacenter pools support academic research pipelines with configurable per-IP rate limits, pool sizes from 4 to 100+ IPs for any corpus scale, and US and EU geo-targeted IPs for regional academic database access.
-
Conclusion
The research data collection challenge is straightforward to frame: over 7.5 million papers published annually (STM Association, 2023), a global literature of hundreds of millions of documents, and academic APIs designed for individual researcher use rather than institutional-scale corpus construction. Proxy infrastructure fills the gap between what academic APIs explicitly permit and what those APIs can deliver to a single IP address.
The configuration approach for research data collection differs from commercial web data workloads in one important respect: most academic data sources publish their rate limits, document their access policies, and explicitly permit bulk research use. The job of the proxy layer is not to evade these policies — it is to make them work at research scale by distributing throughput across IPs that each stay within documented limits.
The biggest efficiency gain available to most computational researchers building proxy infrastructure for data collection isn't better rotation — it is using the right sources. OpenAlex and Semantic Scholar cover Google Scholar use cases with documented APIs and explicit permissions. arXiv provides bulk S3 exports that bypass per-request rate limits entirely for full corpus work. PubMed Central's Open Access FTP is the fastest path to millions of full-text papers. Combined with proxy infrastructure for sources where per-request collection is necessary, these options make multi-million-paper corpus construction a pipeline engineering challenge rather than an infrastructure one.
Using Proxies for Academic Research Data Collection: Guide
More than 7.5 million academic papers are published every year (STM Association, 2023). PubMed alone indexes over 35 million citations. arXiv carries more than 2.3 million preprints across physics, mathematics, computer science, and adjacent fields. The full-text content of this literature, along with citation networks, author metadata, publication timelines, and funding information, forms the raw material for computational research in natural language processing, bibliometrics, science of science, and computational social science.
The problem for researchers who want to collect this data programmatically is not access — most academic databases explicitly permit machine access under their terms. The problem is infrastructure. Publisher platforms, preprint servers, and database interfaces impose per-IP rate limits to manage server load, and research institutions running collection jobs from shared IP ranges hit those limits almost immediately. A research server at a university might share its outbound IP with dozens of other automated jobs across departments. A single collection run that makes 1,000 API calls can exhaust the rate allowance for the entire institution's IP block within minutes.
An academic research proxy routes collection requests through rotating IPs so that per-IP rate limits don't terminate collection jobs mid-run, geographic access restrictions don't create coverage gaps, and institutional IP blocks don't propagate to downstream databases. This guide covers the use cases, configuration, source compatibility, and ethical framework for proxy-based academic data collection.
[INTERNAL-LINK: what are datacenter proxies → overview of datacenter proxy infrastructure and rotating IP pool mechanics]
Key Takeaways
- Over 7.5 million academic papers are published annually (STM Association, 2023) — large-scale collection requires proxy infrastructure to stay within per-source rate limits
- PubMed's official rate limit is 10 requests/second without API key, 10 requests/second with key — shared institutional IPs exhaust this in seconds across concurrent jobs
- The global research data management market is valued at $1.2 billion and growing at 19% CAGR (MarketsandMarkets, 2024) — infrastructure investment follows data volume
- Most major academic data sources (PubMed, arXiv, CrossRef, CORE) explicitly permit programmatic access with stated rate limits — proxy infrastructure makes those limits usable at research scale
Table of Contents
- Why Academic Researchers Need Proxy Infrastructure
- The Shared IP Problem in Research Institutions
- What Is an Academic Research Proxy?
- What Data Do Researchers Collect Using Proxies?
- How to Configure Proxies for Research Data Collection
- Respecting Rate Limits and Polite Access Patterns
- Which Academic Data Sources Work with Datacenter Proxies?
- What Are the Ethical and Legal Considerations?
- Frequently Asked Questions
- Conclusion
Why Academic Researchers Need Proxy Infrastructure
Computational research at scale requires data collection infrastructure that most research institutions are not architected to support. The problem has three layers:
Shared outbound IP addresses: Universities and research institutions route outbound traffic through shared IP pools or NAT gateways. A computer science lab running a corpus collection job, a sociology department running a social media collection pipeline, and a library's automated cataloging system may all appear on the public internet as the same IP address or small IP range. When one of these jobs hits a rate limit, the database or API provider rate-limits the IP — which affects all concurrent and subsequent requests from the entire institution's network. A single aggressive collection run can inadvertently block all programmatic access from an institution for hours.
Rate limits that assume single-user access: Most academic database rate limits are designed for individual researcher access, not institutional-scale collection. CrossRef's polite pool allows 50 requests/second for registered users — generous for a single researcher, but a 5-million-DOI corpus traversal at 50 req/sec takes 27 hours from a single registered IP. PubMed's NCBI E-utilities API allows 10 requests/second with an API key, which sounds fast until you're collecting 35 million records with metadata.
Geographic access controls on regional data: Some academic databases, government research repositories, and national library systems apply geographic access controls. European open-access repositories, national statistical offices, and some regional journal platforms restrict access to IP ranges associated with institutions in their jurisdiction. Research requiring cross-national data coverage requires proxy IPs in the relevant regions.
What we've found: The most common proxy use case in academic research isn't circumventing paywalls — it's distributing load across IPs to comply with per-IP rate limits while completing collection jobs within a reasonable timeframe. A researcher building a 10-million-paper NLP training corpus from PubMed Central's Open Access subset can do so within the explicit terms of PMC's bulk data access policy; the proxy infrastructure just makes the timeline practical (hours vs. weeks from a single IP). The access is permitted; the proxy makes it feasible.
What Is an Academic Research Proxy?
An academic research proxy is a proxy server used to route automated scholarly data collection requests through rotating IP addresses. It provides the network layer between a research collection pipeline and academic data sources — databases, APIs, preprint servers, publisher portals — distributing request volume so per-IP rate limits don't terminate multi-day collection jobs.
In a research context, proxy infrastructure serves three distinct functions:
Rate distribution across IP pool: Spreading API calls and web requests across multiple IPs so that each IP's request rate stays within the rate limits published by the data source. For a 10-req/sec API limit, 10 IPs rotating in round-robin each make 1 request/sec — well within the individual limit, with 10x aggregate throughput.
Job isolation between research projects: Assigning separate proxy pools or IP subsets to different collection projects prevents one project's rate limit violations from affecting another. A lab running simultaneous corpus collection jobs for three separate grants benefits from IP-level project isolation.
Geographic coverage for regional sources: Routing requests through IPs in the relevant country or region for data sources that apply geographic access controls, ensuring complete coverage of regional academic databases without institutional geo-restriction.
[INTERNAL-LINK: datacenter vs residential proxies → which proxy type best fits structured API-based data collection workloads]
What Data Do Researchers Collect Using Proxies?
Academic data collection spans a wide range of source types and research applications. The workloads break down by data category and downstream research use:
Full-text paper corpora: Bulk collection of research papers, preprints, and technical reports from PubMed Central Open Access, arXiv, SSRN, CORE, Semantic Scholar, and other open-access repositories. Used for NLP model training, topic modeling, citation analysis, and science-of-science research. arXiv alone adds approximately 20,000 new preprints per month — continuous corpus maintenance requires recurring collection runs.
Citation and reference networks: DOI-level citation data from CrossRef, OpenCitations, and Semantic Scholar APIs. Used to construct academic knowledge graphs, measure research impact, identify influential papers, and study the diffusion of ideas across disciplines. CrossRef's API provides metadata for over 150 million DOIs — traversal at scale requires rotating IP infrastructure to stay within rate limits.
Author and affiliation data: Researcher profiles, institutional affiliations, ORCID identifiers, and publication histories from OpenAlex, ORCID public data, and institutional repository APIs. Used for researcher career trajectory analysis, collaboration network mapping, and gender/diversity research in academia.
Web content for social science research: News articles, social media archives, political speech archives, government records, and public discourse data for computational social science and political science research. This category involves the broadest range of sources and often requires JavaScript rendering alongside proxy rotation.
Dataset and code availability tracking: Tracking data sharing and code availability statements in published papers, repository links on GitHub, Zenodo, and Figshare, and software citations. Used by open science researchers studying replication practices and research transparency trends.
Conference and preprint metadata: Paper submission data, acceptance rates, reviewer assignments (where public), and presentation records from conference management systems and preprint server APIs. Used for studying peer review patterns and publication bias.
[INTERNAL-LINK: web scraping use cases → guide to automated data collection pipelines for research and analysis workloads]
How to Configure Proxies for Research Data Collection
Academic data collection has configuration requirements that differ from commercial web data workloads. The priority hierarchy is different: data completeness and accuracy matter more than collection speed, most sources have published rate limits (rather than undocumented thresholds), and the ethical obligation to be a polite API citizen is higher in research contexts than in commercial ones.
Respecting Rate Limits and Polite Access Patterns
The correct mental model for proxy use in academic research is not "evading rate limits" — it's "distributing your legitimate aggregate throughput across multiple IPs so that per-IP rate limits accommodate your total collection volume." Most academic data sources publish their rate limits and explicitly permit programmatic access. Proxy infrastructure makes those rate limits work at research scale.
A production academic corpus collector with per-source rate configuration, polite headers, and retry logic:
```python
import requests
import time
import random
import logging
from datetime import datetime, timedelta
from typing import Optional
from dataclasses import dataclass, field
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
@dataclass
class SourceConfig:
"""Per-source rate limit and access configuration for academic APIs."""
base_url: str
req_per_second: float # Stay at 80% of published limit for safety margin
contact_email: str # Used in User-Agent for polite pool access
api_key: Optional[str] = None
requires_key_header: bool = False
Configuration for major academic data sources
SOURCE_CONFIGS = {
"pubmed": SourceConfig(
base_url="https://eutils.ncbi.nlm.nih.gov/entrez/eutils/",
req_per_second=8.0, # Published limit: 10/sec with API key; use 80%
contact_email="[email protected]",
api_key="YOUR_NCBI_API_KEY",
),
"crossref": SourceConfig(
base_url="https://api.crossref.org/",
req_per_second=40.0, # Polite pool: 50/sec; use 80%
contact_email="[email protected]",
),
"arxiv": SourceConfig(
base_url="https://export.arxiv.org/api/",
req_per_second=2.0, # arXiv asks for 3-second delays; 2/sec is conservative
contact_email="[email protected]",
),
"openalex": SourceConfig(
base_url="https://api.openalex.org/",
req_per_second=8.0, # Published limit: 10/sec with polite pool
contact_email="[email protected]",
),
}
PROXY_POOL = [
"http://user:pass@dc-proxy1:port",
"http://user:pass@dc-proxy2:port",
"http://user:pass@dc-proxy3:port",
Pool size: (target_req_per_second / safe_req_per_ip_per_second) IPs
For CrossRef at 40 req/sec with 5 req/ip/sec safe rate: ~8 IPs minimum
]
ip_last_used: dict[str, datetime] = {}
MIN_IP_INTERVAL = 1.0 # Minimum seconds between reuses of any single IP
def build_headers(config: SourceConfig) -> dict:
"""
Build polite request headers identifying the research project.
Academic APIs use the User-Agent and mailto parameter for polite pool routing.
"""
headers = {
"User-Agent": f"ResearchCollector/1.0 (mailto:{config.contact_email})",
"Accept": "application/json",
}
if config.requires_key_header and config.api_key:
headers["Authorization"] = f"Bearer {config.api_key}"
return headers
def get_proxy() -> Optional[str]:
"""Return an available proxy IP respecting minimum reuse interval."""
now = datetime.now()
available = [
p for p in PROXY_POOL
if (now - ip_last_used.get(p, datetime.min)).total_seconds() >= MIN_IP_INTERVAL
]
return random.choice(available) if available else None
def fetch_academic(url: str, source_key: str, params: dict = None) -> Optional[dict]:
"""
Fetch academic API data with polite rate limiting and proxy rotation.
Enforces per-source rate limits and provides structured retry with backoff.
"""
config = SOURCE_CONFIGS[source_key]
min_interval = 1.0 / config.req_per_second
headers = build_headers(config)
Add API key as query param where required (e.g., NCBI)
if params is None:
params = {}
if config.api_key and not config.requires_key_header:
params["api_key"] = config.api_key
for attempt in range(3):
proxy = get_proxy()
if proxy:
ip_last_used[proxy] = datetime.now()
proxies = {"http": proxy, "https": proxy} if proxy else None
try:
resp = requests.get(
url, params=params, headers=headers,
proxies=proxies, timeout=30,
)
if resp.status_code == 200:
return resp.json()
if resp.status_code == 429:
retry_after = int(resp.headers.get("Retry-After", 60))
logging.warning(f"Rate limited by {source_key} — waiting {retry_after}s")
time.sleep(retry_after)
continue
logging.warning(f"{source_key} returned {resp.status_code} for {url}")
except requests.RequestException as e:
logging.error(f"Request error for {source_key}: {e}")
time.sleep(min_interval * (2 ** attempt)) # Exponential backoff on failure
return None
Example: collect metadata for a set of DOIs via CrossRef
DOIS = [
"10.1038/s41586-021-03819-2",
"10.1126/science.abm4003",
"10.1145/3442188.3445922",
]
for doi in DOIS:
url = f"https://api.crossref.org/works/{doi}"
result = fetch_academic(url, "crossref")
if result:
title = result.get("message", {}).get("title", ["[no title]"])[0]
logging.info(f"Collected: {title[:60]}")
time.sleep(1.0 / SOURCE_CONFIGS["crossref"].req_per_second)
```
Key configuration decisions for academic data collection:
Always include a contact email in the User-Agent: CrossRef, OpenAlex, and several other academic APIs route requests with a mailto: identifier in the User-Agent to a dedicated "polite pool" with higher rate limits and better availability. This is not just good practice — it is the documented mechanism for accessing the higher-tier service level. Omitting it means your requests go to the shared pool with lower limits.
Configure per-source rate limits explicitly: Different academic data sources have different limits that differ by API key tier, registered use, and endpoint. Hard-code each source's limit in a configuration object and enforce it in code rather than using a single global rate. CrossRef allows 40+ req/sec in the polite pool; arXiv requests 3-second delays. Treating them the same wastes CrossRef capacity and violates arXiv's access guidelines.
Use exponential backoff on 429 responses, not simple retry: Academic API servers are shared infrastructure. A 429 means the server is asking you to back off — respecting Retry-After headers and implementing exponential backoff on subsequent 429s is both correct behavior and more effective than immediate retry.
[INTERNAL-LINK: how to rotate proxies in python → complete guide to rate-aware proxy rotation for API-based data collection]
Which Academic Data Sources Work with Datacenter Proxies?
What we've found: Google Scholar is the first source most researchers think of for citation data — and the worst option for programmatic collection. Google Scholar has no official API, actively blocks automated access, and applies aggressive IP-based blocks. The correct alternative is Semantic Scholar (100 req/sec with API key, research use explicitly permitted, 200+ million papers indexed) or OpenAlex (full open-access, 10 req/sec in polite pool, complete coverage of academic literature with OA status flags). Both provide better machine-readable data than Scholar's web interface, with documented rate limits and explicit research use permissions. Teams investing collection infrastructure in Scholar are solving the wrong problem.
Proxy pool sizing for academic data workloads:
| Dataset Target | Source | Requests Needed | Pool Size | Collection Time |
|---|---|---|---|---|
| 1M paper metadata | CrossRef API | 1M requests | 4-6 IPs | ~7 hours at 40 req/sec |
| 10M paper metadata | OpenAlex API | 10M requests | 6-10 IPs | ~14 hours at 10 req/sec (paginated) |
| 35M PubMed citations | NCBI E-utilities | 35M requests | 8-12 IPs | ~50 hours at 10 req/sec |
| arXiv full corpus | arXiv API (bulk) | Use bulk S3 data | N/A — use S3 export | Hours (S3 preferred) |
| 500K DOI metadata | CrossRef (polite) | 500K requests | 2-4 IPs | ~3.5 hours at 40 req/sec |
[INTERNAL-LINK: proxy pool sizing guide → how to calculate IP pool requirements for API-based data collection at research scale]
What Are the Ethical and Legal Considerations?
Academic data collection with proxies operates under a clearer ethical and legal framework than commercial web data collection, because most academic data sources are specifically designed for programmatic research access. The framework has distinct layers:
Sources with explicit bulk access permissions: PubMed Central's Open Access subset, arXiv, CrossRef, OpenAlex, and CORE all explicitly document and permit bulk programmatic access in their access policies. NCBI (PubMed) provides a dedicated bulk download pathway via FTP/S3 for researchers who need full corpus access. Using proxy infrastructure to stay within per-IP rate limits while accessing these sources is straightforwardly within the terms of use — you are accessing permitted data within documented technical constraints.
Text and data mining (TDM) rights for licensed content: In the EU, the Copyright in the Digital Single Market Directive (Article 4) establishes a mandatory exception permitting text and data mining of lawfully accessed content for research purposes. In the US, fair use analysis generally supports non-commercial research TDM. Major publishers (Elsevier, Springer, Wiley) operate dedicated TDM APIs for institutional subscribers, providing structured programmatic access to licensed content without requiring web scraping.
The difference between rate distribution and circumvention: Using proxies to distribute legitimate aggregate throughput across IPs — staying within each source's rate limits while achieving research-scale collection — is different from using proxies to circumvent access controls. The former respects the source's technical infrastructure; the latter doesn't. The ethical line tracks the technical distinction: staying within published rate limits via IP distribution is polite access at scale; exceeding them or bypassing authentication is not.
Human subjects research and IRB scope: If collected data includes information about identifiable individuals — author publication records, research career data, collaborative network data — IRB (Institutional Review Board) review may apply depending on research institution policy and funding source requirements. Pure bibliometric data (publication counts, citation networks, funding acknowledgments) typically falls outside human subjects research definitions. Consult your institution's IRB guidance for data involving individual researcher identification.
Data sharing and reproducibility obligations: Research using collected academic datasets is increasingly subject to data availability requirements from journals and funders. If the collected dataset is derived from sources with usage restrictions (publisher TDM APIs, licensed databases), downstream data sharing may be limited. Datasets derived from fully open sources (PubMed OA, arXiv, OpenAlex) can typically be shared and published without restriction.
Reliable Proxy Infrastructure for Research Data Collection
SparkProxy's datacenter pools support academic research pipelines with configurable per-IP rate limits, pool sizes from 4 to 100+ IPs for any corpus scale, and US and EU geo-targeted IPs for regional academic database access.
Frequently Asked Questions
What is an academic research proxy?
An academic research proxy is a proxy server used to route automated scholarly data collection requests through rotating IP addresses. It enables researchers to collect large-scale paper corpora, citation networks, and bibliometric datasets from academic APIs and databases without the per-IP rate limits causing collection jobs to stall. Rather than circumventing rate limits, proxy infrastructure distributes legitimate aggregate throughput across multiple IPs so each IP's request rate stays within published limits while total collection throughput scales to research corpus sizes.
Is it ethical to use proxies for academic data collection?
Yes, when used to distribute load while respecting per-source rate limits on databases that explicitly permit programmatic access. The ethical distinction is between rate distribution (distributing legitimate throughput across IPs, with each IP staying within published limits) and circumvention (bypassing access controls or exceeding published limits via IP rotation). For sources like CrossRef, PubMed, OpenAlex, and arXiv — which explicitly permit and document bulk programmatic access — proxy infrastructure that stays within per-IP rate limits is consistent with intended use.
Which academic databases have official APIs for bulk data collection?
The major sources with official programmatic access documentation: PubMed/NCBI E-utilities (10 req/sec with API key; bulk FTP/S3 for full corpus), CrossRef (50 req/sec in polite pool), arXiv (API with 3-second delay; bulk S3 export for full corpus), OpenAlex (10 req/sec with polite pool; full database snapshots via OpenAlex data), Semantic Scholar (100 req/sec with API key), CORE (tiered API access), and ORCID (public data API). Publisher-licensed content is available through Elsevier TDM, Springer Nature TDM, and Wiley TDM APIs for institutional subscribers.
How many proxies do I need for a 10-million-paper corpus collection?
For CrossRef at 40 requests/second (80% of polite pool limit), collecting 10 million DOI records requires approximately 10 million requests. At 40 req/sec continuous, that takes roughly 70 hours. With 6-8 IPs rotating, each IP handles approximately 5-7 requests/second — within safe per-IP margins. For PubMed at 10 req/sec, the same 10 million record collection takes ~280 hours from a single IP; 10-12 IPs bring this to 25-30 hours. The right pool size depends on the target source's documented rate limit, not just the corpus size.
Can I use proxies to collect data from Google Scholar for research?
Google Scholar is not recommended for programmatic research data collection regardless of proxy approach. It has no official API, actively blocks automated access, and applies aggressive behavioral detection. More importantly, two superior alternatives exist: Semantic Scholar provides equivalent or better coverage (200+ million papers) with an official API allowing 100 requests/second, explicit research use permissions, and richer metadata. OpenAlex provides 250+ million works with full open access, an official API, and complete data exports. Both are more comprehensive and more reliable than Scholar for research purposes.
Conclusion
The research data collection challenge is straightforward to frame: over 7.5 million papers published annually (STM Association, 2023), a global literature of hundreds of millions of documents, and academic APIs designed for individual researcher use rather than institutional-scale corpus construction. Proxy infrastructure fills the gap between what academic APIs explicitly permit and what those APIs can deliver to a single IP address.
The configuration approach for research data collection differs from commercial web data workloads in one important respect: most academic data sources publish their rate limits, document their access policies, and explicitly permit bulk research use. The job of the proxy layer is not to evade these policies — it is to make them work at research scale by distributing throughput across IPs that each stay within documented limits.
The biggest efficiency gain available to most computational researchers building proxy infrastructure for data collection isn't better rotation — it is using the right sources. OpenAlex and Semantic Scholar cover Google Scholar use cases with documented APIs and explicit permissions. arXiv provides bulk S3 exports that bypass per-request rate limits entirely for full corpus work. PubMed Central's Open Access FTP is the fastest path to millions of full-text papers. Combined with proxy infrastructure for sources where per-request collection is necessary, these options make multi-million-paper corpus construction a pipeline engineering challenge rather than an infrastructure one.
[INTERNAL-LINK: research data pipeline guide → building production data collection infrastructure for NLP training corpora and bibliometric research]
Frequently Asked Questions
An academic research proxy is a proxy server used to route automated scholarly data collection requests through rotating IP addresses. It enables researchers to collect large-scale paper corpora, citation networks, and bibliometric datasets from academic APIs and databases without the per-IP rate limits causing collection jobs to stall. Rather than circumventing rate limits, proxy infrastructure distributes legitimate aggregate throughput across multiple IPs so each IP's request rate stays within published limits while total collection throughput scales to research corpus sizes.
Yes, when used to distribute load while respecting per-source rate limits on databases that explicitly permit programmatic access. The ethical distinction is between rate distribution (distributing legitimate throughput across IPs, with each IP staying within published limits) and circumvention (bypassing access controls or exceeding published limits via IP rotation). For sources like CrossRef, PubMed, OpenAlex, and arXiv — which explicitly permit and document bulk programmatic access — proxy infrastructure that stays within per-IP rate limits is consistent with intended use.
The major sources with official programmatic access documentation: PubMed/NCBI E-utilities (10 req/sec with API key; bulk FTP/S3 for full corpus), CrossRef (50 req/sec in polite pool), arXiv (API with 3-second delay; bulk S3 export for full corpus), OpenAlex (10 req/sec with polite pool; full database snapshots via OpenAlex data), Semantic Scholar (100 req/sec with API key), CORE (tiered API access), and ORCID (public data API). Publisher-licensed content is available through Elsevier TDM, Springer Nature TDM, and Wiley TDM APIs for institutional subscribers.
For CrossRef at 40 requests/second (80% of polite pool limit), collecting 10 million DOI records requires approximately 10 million requests. At 40 req/sec continuous, that takes roughly 70 hours. With 6-8 IPs rotating, each IP handles approximately 5-7 requests/second — within safe per-IP margins. For PubMed at 10 req/sec, the same 10 million record collection takes ~280 hours from a single IP; 10-12 IPs bring this to 25-30 hours. The right pool size depends on the target source's documented rate limit, not just the corpus size.
Google Scholar is not recommended for programmatic research data collection regardless of proxy approach. It has no official API, actively blocks automated access, and applies aggressive behavioral detection. More importantly, two superior alternatives exist: Semantic Scholar provides equivalent or better coverage (200+ million papers) with an official API allowing 100 requests/second, explicit research use permissions, and richer metadata. OpenAlex provides 250+ million works with full open access, an official API, and complete data exports. Both are more comprehensive and more reliable than Scholar for research purposes.