





Using Proxies for Social Media Monitoring in 2026
67% of brand crises go undetected for 24+ hours without automated social monitoring. Learn how a social media proxy enables reliable, unblocked social listening at scale.

Table of Contents
- Why Social Media Monitoring Requires Proxies?
- What Is a Social Media Proxy?
- Configuring a Social Listening Proxy for Brand Monitoring?
- Multi-Platform Social Monitoring: Proxy Setup by Platform?
- Geo-Targeted Social Monitoring with Location-Matched Proxies?
- Scaling Social Data Collection: Pool Sizing and Cost?
- Conclusion
-
Why Social Media Monitoring Requires Proxies?
The social media monitoring market is worth $5.6 billion in 2024 and projected to reach $15.2 billion by 2030 (MarketsandMarkets, 2024). At the same time, 72% of consumers expect brands to respond to social mentions within one hour (Salesforce, 2024). Those two data points together create a clear infrastructure requirement: monitoring systems that can collect social data continuously without interruption.
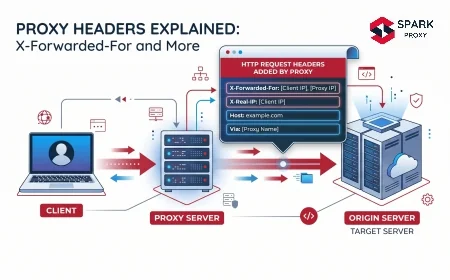
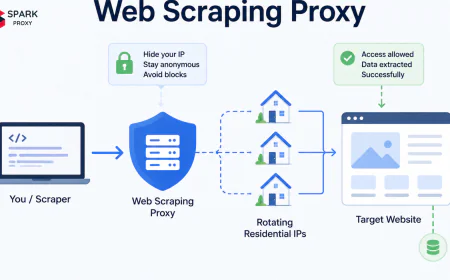
The problem is that social platforms are among the most aggressive when it comes to blocking automated access. Instagram blocks IPs after roughly 100-200 requests per hour without proxy rotation (Apify, 2023). Twitter, LinkedIn, TikTok, and Reddit all have similar or stricter thresholds. A social media proxy solves this by distributing collection requests across a rotating pool of IPs so platforms never see enough requests from a single address to trigger a block.
This guide covers how social media proxies work, why residential IPs outperform datacenter proxies for social platform access, how to configure a social listening proxy for continuous brand monitoring, and the specific setup patterns for multi-platform social data collection at scale.
Key Takeaways
- Instagram blocks IPs after ~100-200 requests/hour without rotation (Apify, 2023); residential proxy pools drop this block rate to under 5%
- Residential proxies achieve 94% social data completeness vs. 61% for datacenter IPs on major platforms (Bright Data, 2024)
- 67% of brand crises go undetected for 24+ hours without automated social monitoring (Mention, 2024) — proxy-backed collection is what keeps monitoring continuous
93% of marketers use social listening to inform strategy (Sprout Social, 2024). The brands doing this effectively are running automated collection — no team manually checks brand mentions across 8.3 platforms simultaneously, which is the average number of platforms brands now track (Hootsuite, 2024). Automation is the only way to achieve the monitoring frequency that makes social listening actionable.
The tension is that social platforms have strong incentives to block automation. They monetize access to their data through official APIs with rate limits and paid tiers. Automated access that bypasses these limits undermines that revenue model. The result is aggressive bot detection: rate limiting, CAPTCHAs, account bans, and IP blocks that terminate monitoring sessions before they produce useful data.
Without proxies, automated social monitoring breaks down predictably:
- Rate limits trigger quickly: High-frequency requests from a single IP hit per-hour limits within minutes on Instagram, TikTok, and Facebook
- IP reputation signals accumulate: Datacenter IPs are flagged as non-residential by platform detection systems, triggering tighter rate limits or immediate blocks
- Session continuity breaks: Once an IP is flagged, the monitoring session needs to restart from a new IP or wait for the flag to expire — creating data gaps exactly when continuous monitoring matters most
What we've found: The 67% figure on undetected brand crises (Mention, 2024) traces back to monitoring gaps caused by IP blocks, not team inattention. When the proxy pool runs out or rotation fails, monitoring silently drops to partial coverage. Teams see normal-looking dashboards while data collection has already stopped.
-
How Social Platforms Detect and Block Scrapers
Social platforms use layered detection. IP-level rate limits are the first layer — easiest to trigger, easiest to solve with rotation. The deeper layers are behavioral: request timing patterns, header fingerprints, TLS fingerprints, and whether the accessing IP has a residential vs. datacenter origin.
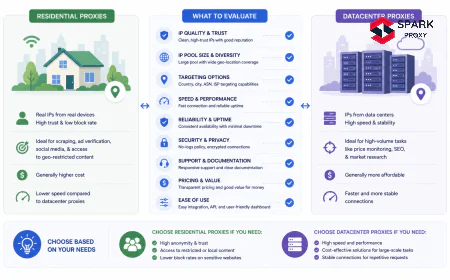
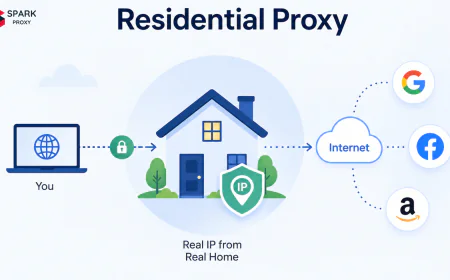
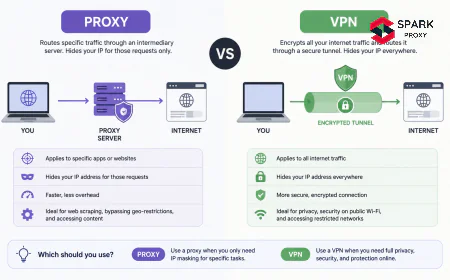
A request coming from an IP registered to a known datacenter (Amazon, Google Cloud, Hetzner) is treated differently from a request that appears to originate from a residential ISP. Many social platforms apply stricter limits to datacenter-origin IPs by default, regardless of request volume. This is why residential proxies, not datacenter proxies, are the standard for social media data collection.
how platforms detect proxy IPs
-
What Is a Social Media Proxy?
A social media proxy is an IP address — typically residential — used to route automated social data collection requests so platforms see traffic from different users and locations rather than a single server. The proxy sits between your monitoring tool and the social platform, presenting each request as coming from a different residential IP.
The practical effect: instead of 500 requests per hour coming from one IP (triggering a block), those requests come from 50 different IPs at 10 requests each — well within per-IP rate limits on most platforms.
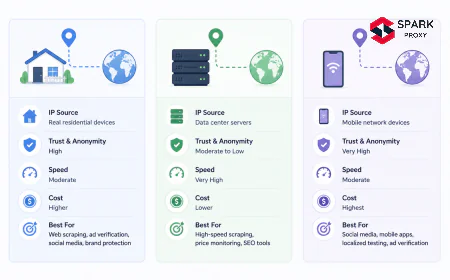
Social media proxies are almost always residential IPs sourced from consumer ISPs, not datacenter IPs. This distinction matters because residential proxies achieve 94% social data completeness vs. 61% for datacenter IPs on major platforms (Bright Data, 2024). The difference reflects platform-level filtering: social networks apply different access rules based on IP origin, and residential IPs pass those filters at much higher rates.
Source: Bright Data, 2024. Data completeness measured across Instagram, Twitter/X, TikTok, and LinkedIn over 30-day collection periods. -
Residential vs. Datacenter Proxies for Social Monitoring
For social media specifically, the proxy type decision is more clear-cut than for most other collection tasks:
| Use Case | Recommended Proxy | Reason |
|---|---|---|
| Instagram monitoring | Residential (rotating) | Instagram aggressively filters datacenter IPs; residential achieves 94% completeness |
| Twitter / X monitoring | Residential (rotating) | API rate limits apply differently by IP type; residential reduces CAPTCHA triggers |
| TikTok public data collection | Residential (rotating) | TikTok uses fingerprinting beyond IP; residential reduces detection surface |
| LinkedIn monitoring | Residential (rotating) | LinkedIn is one of the strictest platforms for automated access |
| Reddit monitoring | Datacenter or Residential | Reddit's API is more accessible; datacenter proxies work for basic collection |
| YouTube comment/metadata | Datacenter acceptable | Less aggressive filtering for public metadata; datacenter works at moderate volume |
| Facebook public page monitoring | Residential (rotating) | Facebook's bot detection is platform-wide; residential strongly preferred |
-
-
Configuring a Social Listening Proxy for Brand Monitoring?
A social listening proxy setup routes each monitoring request through a unique residential IP with enough interval between per-IP requests that no single address accumulates volume. The technical configuration has three components: proxy pool, rotation logic, and session management.
-
Proxy Rotation Strategy for Social Platforms
Unlike SERP scraping where round-robin rotation is often sufficient, social platforms require more careful rotation because they track session behavior across requests, not just per-IP request counts. An IP that makes 20 requests in normal-looking patterns with varied timing is treated differently from one that makes 20 requests at perfectly uniform intervals.
Three rotation adjustments improve social media proxy performance:
Session-based rotation: Assign a proxy IP to a monitoring session (one account profile or one keyword search) for its duration, then rotate to a new IP for the next session. This maintains session continuity per target while distributing load across the pool.
Randomized timing intervals: Add random delays between requests from the same IP — not a fixed interval. Fixed intervals are a bot detection signal. A range of 3-8 seconds between requests is harder to fingerprint than a precise 5-second interval.
Backoff on block signals: When a request returns a 429, 403, or CAPTCHA response, immediately retire that IP from the active rotation pool for 30-60 minutes. Don't retry the same IP — move to the next available IP and mark the retired IP for cooldown.
A Python implementation with session-based rotation and backoff:
```python
import requests
import random
import time
from datetime import datetime, timedelta
Proxy pool: residential IPs from your provider
PROXY_POOL = [
"http://user:pass@res-proxy1:port",
"http://user:pass@res-proxy2:port",
"http://user:pass@res-proxy3:port",
expand to full pool
]
Track cooldown state
cooldown_until = {}
def get_available_proxy():
now = datetime.now()
available = [
p for p in PROXY_POOL
if cooldown_until.get(p, now) <= now
]
if not available:
raise RuntimeError("All proxies in cooldown — expand pool or wait")
return random.choice(available)
def fetch_social_data(url, headers):
proxy = get_available_proxy()
try:
resp = requests.get(
url,
proxies={"http": proxy, "https": proxy},
headers=headers,
timeout=20,
)
if resp.status_code in (429, 403):
Put proxy in 45-minute cooldown
cooldown_until[proxy] = datetime.now() + timedelta(minutes=45)
return None
return resp.text
except requests.RequestException:
cooldown_until[proxy] = datetime.now() + timedelta(minutes=30)
return None
Randomized delay between requests
time.sleep(random.uniform(3.0, 8.0))
```
What we've found: The backoff duration matters more than most teams expect. A 5-minute cooldown after a 429 is insufficient for Instagram and TikTok — these platforms maintain rate limit state for 30-60 minutes. Proxies returned to rotation too early re-trigger blocks immediately, which burns through the pool faster than necessary. 45 minutes is the reliable floor for major social platforms.
-
-
Multi-Platform Social Monitoring: Proxy Setup by Platform?
Brands track an average of 8.3 social platforms simultaneously (Hootsuite, 2024). Each platform has different rate limits, detection sensitivity, and proxy type requirements. A single unified proxy pool can serve all platforms, but optimal configuration uses platform-segmented rotation to prevent a block on one platform from contaminating the proxy pool used for another.
Instagram: Most restrictive. Use a dedicated residential proxy pool. Limit to 80-120 requests per IP per hour. Session-based rotation recommended. Public profile data and hashtag monitoring require different endpoints with different thresholds.
Twitter / X: Rate limits apply at the API key level as well as IP level for API-based access. For web scraping (non-API), residential proxies with 60-90 second intervals between same-IP requests work reliably. Block signals appear as redirects to login pages rather than 429 errors — include a check for unexpected redirects in your retry logic.
TikTok: Public data collection is possible through TikTok's web interface. TikTok applies JavaScript fingerprinting as well as IP filtering, so proxy rotation alone isn't sufficient without also managing browser fingerprints for headless browser-based collection. Residential proxies are required; datacenter IPs are filtered at the CDN level.
LinkedIn: The most restrictive platform for automated access outside of official API. LinkedIn's bot detection is session-aware and blocks based on behavioral patterns rather than just request volume. Best practice is very low frequency (10-15 requests/hour per IP) with residential proxies and proper browser header simulation.
Reddit: More permissive than the major social platforms. Reddit's official API allows programmatic access with proper authentication, and rate limits are well-documented. For web scraping, datacenter proxies work at moderate volume. For high-frequency monitoring, residential proxies reduce friction.
Facebook: Public page and group monitoring requires residential proxies. Facebook's bot detection has improved substantially since 2023 and now flags datacenter IPs on most collection patterns. Session-sticky residential IPs (same IP for multiple requests within a browsing session) work better than per-request rotation for Facebook.
Source: Apify, 2023; Bright Data, 2024. Red = high restriction, amber = moderate, green = permissive. Limits apply to residential proxy IPs with session-based rotation.
-
Geo-Targeted Social Monitoring with Location-Matched Proxies?
Geo-targeted social proxies surface up to 40% more locally relevant brand mentions (Oxylabs, 2024). Social platforms serve geo-localized content — trending topics, local news feeds, location-tagged posts, and regional hashtags — that only appear when the accessing IP is registered in the target geography. A brand monitoring tool running from a single US-based IP misses locally relevant content in other markets entirely.
For multi-market brand monitoring, the proxy pool needs geographic coverage matched to your monitoring target list:
- Country-level geo-targeting: Sufficient for tracking brand mentions in national markets. A UK-registered residential IP surfaces UK-trending topics and UK-specific social content that a US IP won't see.
- City-level geo-targeting: Required for local brand monitoring, local competitor tracking, and location-tagged content collection. A New York IP sees different trending local conversations than a Los Angeles IP for the same brand query.
- Language-matched proxies: For non-English monitoring, combining geo-matching with language settings (
hlorlangparameters where applicable) improves content relevance.
Practical configuration for multi-market social monitoring:
```python
Example: geo-targeted monitoring session config
MARKET_PROXY_MAP = {
"us": ["http://user:pass@us-res-proxy1:port", "http://user:pass@us-res-proxy2:port"],
"gb": ["http://user:pass@uk-res-proxy1:port", "http://user:pass@uk-res-proxy2:port"],
"de": ["http://user:pass@de-res-proxy1:port", "http://user:pass@de-res-proxy2:port"],
"au": ["http://user:pass@au-res-proxy1:port", "http://user:pass@au-res-proxy2:port"],
}
def get_proxy_for_market(market_code):
pool = MARKET_PROXY_MAP.get(market_code, [])
if not pool:
raise ValueError(f"No proxies configured for market: {market_code}")
return random.choice(pool)
```
This pattern assigns each monitoring task to a geo-matched proxy, ensuring the social content you collect reflects what users in each target market actually see. For brands running global campaigns, this is the difference between monitoring your actual audience's social environment and monitoring a US-centric view of a global conversation.
[INTERNAL-LINK: geo-targeted proxy guide → how to configure location-specific proxies for market-accurate data collection]
-
Scaling Social Data Collection: Pool Sizing and Cost?
Proxy pool sizing for social monitoring follows the same core formula as other scraping workloads but with tighter per-platform limits. The most restrictive platform in your monitoring set determines your minimum pool size.
Sizing formula:
- Per-IP hourly limit (conservative): 60-100 requests for most platforms (15-30 for LinkedIn and TikTok)
- Formula: (total daily requests across all platforms) ÷ (hourly limit × monitoring hours) = minimum pool size
- Example: Brand monitoring 5 platforms at 200 requests each per hour for 16 hours = 16,000 daily requests ÷ (80 req/hour × 16 hours) = 12.5 → minimum 13 IPs
Per-platform pool segmentation (recommended for scale):
| Platform | Conservative Limit | Recommended Pool per 1K Daily Requests |
|---|---|---|
| LinkedIn | 15 req/IP/hr | 8-10 IPs |
| TikTok | 30 req/IP/hr | 4-5 IPs |
| Instagram | 100 req/IP/hr | 1-2 IPs |
| Facebook | 80 req/IP/hr | 2-3 IPs |
| Twitter/X | 60 req/IP/hr | 2-3 IPs |
| Reddit | 120 req/IP/hr | 1 IP |
Cost comparison: Residential proxies cost $8-15/GB vs. $1-3/GB for datacenter. Social monitoring requests are typically lightweight (5-20KB per response for JSON/HTML), so bandwidth costs are modest even at scale. A monitoring program generating 50,000 requests/day at 10KB average = 500MB/day → roughly $4-7/day in residential proxy bandwidth. That's a low cost for continuous brand monitoring that prevents the 67% crisis detection gap documented by Mention.
Keep Social Monitoring Running Without Gaps
SparkProxy's residential proxy pool covers 150+ countries with city-level geo-targeting, dedicated rotation pools for social platforms, and real-time pool health monitoring to keep your social listening infrastructure online.
-
Conclusion
Automated social media monitoring at scale requires two infrastructure elements: residential proxies to pass platform detection systems, and rotation logic that keeps per-IP request rates below platform thresholds. Without both, monitoring systems produce the data gaps that let brand crises go undetected for 24+ hours.
The setup is straightforward once you match it to your platform requirements. LinkedIn and TikTok need small, slow pools. Instagram and Facebook need residential proxies but tolerate higher per-IP rates. Reddit and YouTube are more permissive. Configure platform-segmented rotation, implement 45-minute cooldowns on blocked IPs, and size pools at 125% of your monitoring volume to handle spikes.
For multi-market monitoring, add geo-matched residential IPs per target market. The 40% increase in locally relevant brand mentions that geo-targeting provides is the difference between monitoring your global conversation and monitoring a US-filtered version of it.
Frequently Asked Questions
Yes, if you're running automated monitoring at any meaningful scale. Without proxies, platforms block high-frequency requests from single IPs — Instagram triggers blocks at roughly 100-200 requests per hour (Apify, 2023), and data completeness without proxies is around 35% on major platforms. For continuous brand monitoring, a residential proxy pool is the infrastructure layer that keeps collection running without gaps.
[INTERNAL-LINK: social listening setup guide → step-by-step configuration for proxy-based social monitoring]
Social platforms distinguish between residential and datacenter IP origins. Residential IPs pass as consumer user traffic; datacenter IPs are immediately flagged as server-origin traffic and subject to stricter rate limits or direct blocks. Residential proxies achieve 94% data completeness vs. 61% for datacenter IPs (Bright Data, 2024). For social media specifically, using datacenter proxies costs you a third of your potential data before any rate limits even apply.
It depends on your platform mix and request volume. For LinkedIn and TikTok (most restrictive), plan for 8-10 residential IPs per 1,000 daily requests. For Instagram and Facebook, 2-3 IPs per 1,000 daily requests is workable. A brand monitoring 5 major platforms at moderate volume typically needs 20-50 residential IPs. Add 25% buffer for cooldowns and retries.
You can, but platform-segmented pools perform better. A block signal from aggressive Instagram collection can push IPs into cooldown that you needed for LinkedIn monitoring. Separate pools per platform — or at minimum per sensitivity tier — prevent one platform's rate limits from disrupting your monitoring across all properties.
Collecting publicly accessible social data is generally legal in most jurisdictions. US courts have ruled that scraping publicly available data doesn't violate the Computer Fraud and Abuse Act. The relevant limits are: data must be publicly accessible (no login bypass), collection must not involve personal data that triggers GDPR or CCPA obligations, and you must comply with each platform's Terms of Service for commercial use cases. Consult legal counsel for your specific use case, particularly for EU markets.