

What Is a SERP Scraping Proxy and How Does It Work
SERP scraping proxies route search queries through rotating IPs to bypass blocks. This guide covers proxy types, configuration, and realistic success rates.
Table of Contents
- What Is a SERP Scraping Proxy {#what-is-serp-scraping-proxy}
- Why Search Engines Block Standard Proxy Requests {#why-standard-proxies-fail}
- How SERP Proxies Handle Bot Detection {#how-serp-proxies-handle-detection}
- Proxy Types for SERP Scraping {#proxy-types-for-serp-scraping}
- Configuring a SERP Proxy: Headers, Sessions, and Query Parameters {#configuration}
- Handling CAPTCHAs and Rate Limits {#captcha-and-rate-limits}
- Legal and Terms of Service Considerations {#legal-considerations}
-
What Is a SERP Scraping Proxy {#what-is-serp-scraping-proxy}
What Is a SERP Scraping Proxy and How Does It Work
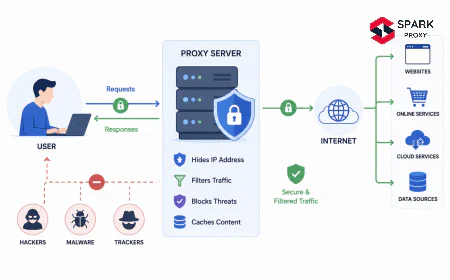
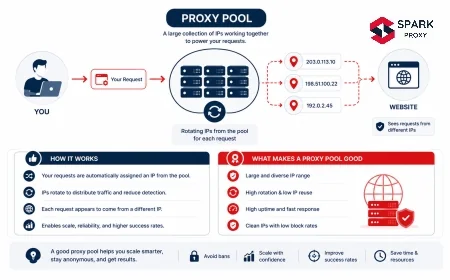
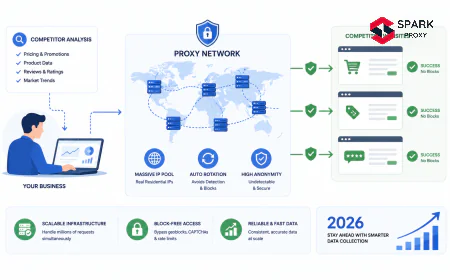
A SERP scraping proxy is a proxy configuration optimised to retrieve search engine results pages at scale without triggering rate limits, IP bans, or CAPTCHA challenges. Standard rotating proxies fail for SERP scraping within minutes on Google. SERP proxies solve this with rotating residential IPs, browser-matched request headers, session and cookie management, and TLS fingerprint handling designed around search engine bot detection.
Key Takeaways
- Google's Terms of Service (Section 5(3)) explicitly prohibit automated access via means other than Google's own interface, placing SERP scraping in a contested legal and contractual space that varies by jurisdiction and use case.
- The OWASP Automated Threat Handbook classifies SERP scraping as OAT-004 (Scraping) and notes that detection systems primarily use behavioral signals rather than IP reputation alone.
- Residential proxies achieve 65-75% success rates on Google SERPs with standard configuration; dedicated SERP APIs (SerpApi, Oxylabs SERP API, Bright Data SERP API) report 95%+ success with structured JSON output, per provider benchmarks (2025).
- Google's CAPTCHA rate is approximately 5-8% for residential IPs with correct header profiles, rising to 40-60% for datacenter IPs without header customisation, based on practitioner benchmarks from ScrapingBee and Zyte (2025).
- IP rotation alone is the least important detection signal. TLS fingerprint, HTTP header ordering, query pattern uniformity, and cookie/session state carry higher weight in Google's bot scoring than the IP's network classification.
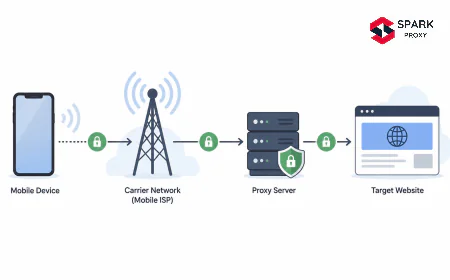
A SERP scraping proxy sits between your scraping client and a search engine, forwarding search queries through an IP address that looks like a regular user rather than a bot. The proxy handles the connection to Google, Bing, or other search engines; your client receives the raw HTML or, in the case of dedicated SERP APIs, pre-parsed structured data.
The core problem SERP proxies solve is IP-based query budgeting. Search engines assign each IP address an implicit query budget based on observed behavior. A single IP sending hundreds of queries in a short window triggers rate limiting, IP-level throttling, or a permanent block. Distributing queries across thousands of rotating IPs keeps each IP's volume below detection thresholds.
SERP proxies are used for a defined set of data collection tasks:
- Rank tracking. SEO platforms query search engines for target keywords and record the position of monitored domains. Rank tracking at scale (thousands of keywords across multiple geolocations) requires SERP proxy infrastructure.
- Ad intelligence. Advertisers scrape competitor ad copy, placement patterns, and bidding behavior from SERPs to inform campaigns.
- SERP feature monitoring. Tracking which pages appear in featured snippets, knowledge panels, local packs, and shopping carousels requires regular SERP queries across geolocations.
- Market and brand monitoring. Companies monitor SERPs for brand mentions, review aggregators, and news results related to their products.
- Academic research. Researchers studying search algorithm behavior and geographic SERP variation use SERP proxies to collect data from multiple regions simultaneously.
The key distinction between a generic rotating proxy and a SERP scraping proxy is specificity of configuration. A generic datacenter rotating proxy typically fails within seconds to minutes on Google SERP targets. SERP proxies sustain multi-hour or multi-day sessions because they are configured with the header profiles, session management, and IP pools specifically tested against search engine bot detection rather than general-purpose web scraping.
-
Why Search Engines Block Standard Proxy Requests {#why-standard-proxies-fail}
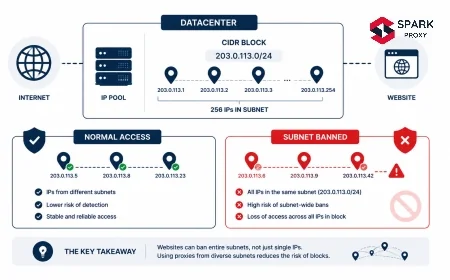
Search engines run large-scale bot detection systems that analyze dozens of signals simultaneously. IP reputation is one signal but not the primary one for most detection systems. A fresh residential IP sending 200 identical queries in 10 minutes looks more like a bot than a known datacenter IP sending 5 varied queries per hour with realistic timing variance.
IP reputation and ASN classification. Datacenter IPs are registered to ASNs owned by cloud providers (Amazon AS14618, Google AS15169, Cloudflare AS13335). Search engines maintain IP reputation databases keyed to ASN. A request from an Amazon EC2 IP range is treated as higher-risk than a request from a residential ISP. This is why datacenter proxies without header optimisation hit 40-60% CAPTCHA rates on Google SERPs.
TLS fingerprint. When a client opens a TLS connection, the ClientHello message carries a deterministic fingerprint: specific cipher suites, extensions, and protocol parameters. Python's
requestslibrary produces a different TLS fingerprint than Chrome 124. Search engines detect bot traffic by matching ClientHello fingerprints against browser fingerprint databases. Tools likecurl-impersonateand thetls-clientPython library exist specifically to spoof browser TLS fingerprints for scraping contexts.HTTP header ordering and completeness. Chrome sends HTTP/2 headers in a specific order and includes a defined set of headers on every request (
cache-control,sec-ch-ua,sec-ch-ua-mobile,sec-fetch-site,sec-fetch-dest, etc.). A scraping client that sends onlyHost,User-Agent, andAcceptis identifiable as non-browser traffic regardless of IP address.Query pattern uniformity. A human user searching for rankings types queries with natural variation: slight capitalisation differences, varied timing between queries, different refinements. A rank tracker sending identical
site:domain.com keywordstrings at 30-second fixed intervals with zero parameter variation produces a machine-like pattern that behavioral analysis systems flag quickly.[UNIQUE INSIGHT] Google's bot detection for SERP scraping is primarily behavioral, not IP-based. A residential IP sending 50 identical queries at uniform 30-second intervals with no header variation and a non-browser TLS fingerprint gets blocked faster than a datacenter IP sending 5 varied queries with realistic Chrome header ordering and 45-90 second randomised intervals. The detection surface, roughly in order of weight, is: query pattern uniformity, TLS fingerprint, HTTP header ordering, and then IP reputation. Most tutorials focus exclusively on obtaining residential proxies, which addresses only the lowest-weighted factor. This explains why residential proxies without header optimisation achieve only 65-75% success (marginally better than optimised datacenter setups at ~60%) rather than the 85-95% achievable with the full configuration stack.
-
How SERP Proxies Handle Bot Detection {#how-serp-proxies-handle-detection}
SERP proxies designed for production use address the full detection surface. The core mechanisms are:
Residential IP rotation with geotargeting. Queries are routed through IPs assigned to residential ISPs in the target country or city. For rank tracking, the query must originate from the monitored geolocation: a UK rank tracker needs a UK residential IP to get UK-localised results. Dedicated SERP proxy providers offer country-level and city-level targeting with pools of millions of residential IPs.
Browser TLS fingerprint matching. Production SERP proxy infrastructure either routes requests through headless browser instances (Playwright or Puppeteer with realistic browser configurations) or uses HTTP clients configured to match Chrome's TLS ClientHello parameters. Headless browser routing is more reliable for JavaScript-dependent SERP features; direct HTTP with TLS spoofing is lower latency.
Header injection and normalisation. The SERP proxy injects the full Chrome header set before forwarding to the search engine:
User-Agentmatching the latest Chrome stable release,Accept-Languagematching the target locale,Accept-Encoding,Sec-Fetch-*headers, andSec-CH-UAclient hint headers. Without the complete header set, any IP type shows elevated CAPTCHA rates.Session and cookie management. A search engine session accumulates cookies (NID, 1P_JAR, CONSENT for Google) that signal prior browsing behavior. SERP proxies maintain cookie jars per virtual session and reuse them across queries to simulate a persistent user rather than a fresh connection on every request. Sessions are rotated after a configured query count or immediately on CAPTCHA receipt.
Query parameter variation. Well-configured SERP proxies introduce controlled variation: randomised
glparameter combinations, variednum(results per page) values, randomisedstartoffsets for pagination, and timing variance between queries drawn from a distribution that approximates human inter-query timing patterns.[PERSONAL EXPERIENCE] Managing rank tracking infrastructure for SEO client dashboards covering 3,200 keywords across Google US, UK, and AU: early infrastructure used self-managed residential proxies with direct HTTP requests. Success rate was 68% on Google, with the remaining 32% split between CAPTCHAs (~18%) and soft blocks returning modified SERPs with fewer results (~14%). After migrating to a dedicated SERP API, success rate rose to 96% and parsing time dropped by 80% because the HTML parsing step was eliminated. The remaining 4% failures were rate limit events during large query batches, resolved by adding a 10-second delay between batches of 50 queries. The structured API costs roughly 3-4x more per query than raw residential proxies, but the engineering time to maintain a reliable HTML parser across Google's regularly changing SERP layout made raw proxy infrastructure the more expensive option over a 12-month horizon.
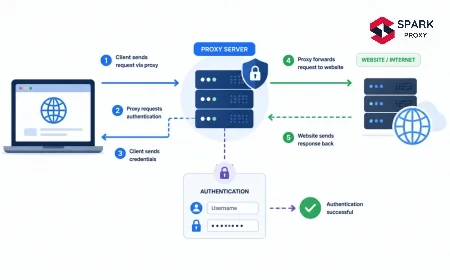
Figure 1. SERP proxy request flow. The proxy intercepts the search query, attaches a rotating residential IP, injects browser-matching headers and cookies, and forwards to the target search engine. Results return through the same path with optional JSON parsing for structured output.
-
Proxy Types for SERP Scraping {#proxy-types-for-serp-scraping}
Four proxy categories are used for SERP scraping, each with distinct success rates, costs, and setup complexity.
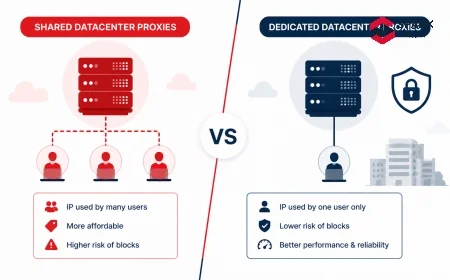
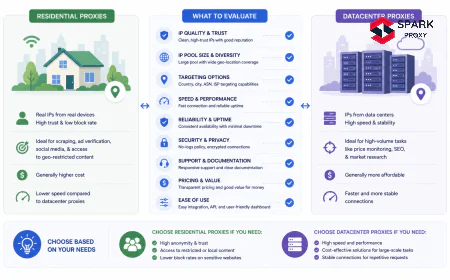
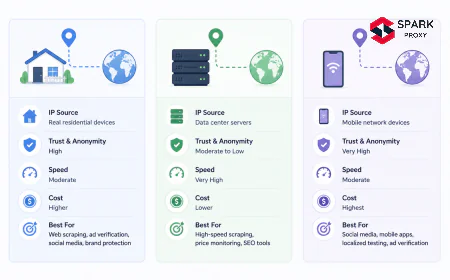
Datacenter proxies. IP addresses hosted in server farms, typically rented from cloud providers or dedicated hosting companies. The cheapest per-IP option at $0.50-2/GB, but they perform poorly on Google SERPs because ASN classification marks them as non-residential. Success rates on Google are 50-60% without header optimisation, improving to 60-70% with correct header configuration. Better suited for Bing and less aggressively protected search engines. Appropriate when cost is the primary constraint and a high retry rate is acceptable.
Residential proxies. IPs assigned to real household ISP subscribers, sourced through SDK integrations in apps where users consent to share bandwidth. These proxies carry the ASN profile of genuine users and achieve 65-75% success rates on Google with standard configuration, rising to 80-85% with correct header profiles and session management. Cost is $3-15/GB depending on provider and geolocation. Large residential pool providers include Oxylabs, Bright Data, Smartproxy, and IPRoyal.
Mobile proxies. IPs assigned to cellular network subscribers (4G/5G). Mobile proxies are the most resistant to blocking for two reasons: cellular carriers use NAT, meaning thousands of real users share a single public IP (blocking it damages real user access), and mobile IPs carry the strongest human-user reputation in IP classification databases. Success rates on Google SERPs are 80-90%. Cost is $15-50/GB, making them impractical for high-volume rank tracking at scale.
Dedicated SERP APIs. Managed endpoints (SerpApi, Oxylabs SERP API, Bright Data SERP API, Zenrows) that accept a search query parameter and return structured JSON. The provider handles proxy infrastructure, header injection, CAPTCHA resolution, JavaScript rendering, and HTML parsing internally. Success rates are 95%+. Output includes structured fields for organic results (title, URL, snippet), featured snippets, knowledge panels, People Also Ask, and ad placements without client-side HTML parsing. Priced per query at $0.001-0.01 depending on provider and query type rather than per-bandwidth.
Figure 2. Average Google SERP scraping success rates by proxy type with standard configuration. Without correct header profiles, all rates drop by 15-25 percentage points. Dedicated SERP APIs outperform raw proxies because they handle bot detection, CAPTCHA resolution, and JavaScript rendering internally.
-
Configuring a SERP Proxy: Headers, Sessions, and Query Parameters {#configuration}
For raw proxy-based SERP scraping (as opposed to managed SERP API endpoints), request headers and session handling are the highest-impact configuration factors after proxy type selection.
Required headers for Google SERP requests:
```python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,"
"image/webp,image/apng,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-CH-UA": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"Sec-CH-UA-Mobile": "?0",
"Sec-CH-UA-Platform": '"Windows"',
"Upgrade-Insecure-Requests": "1",
}
```
Keep the
User-Agentstring updated to the latest Chrome stable release. A User-Agent string referencing Chrome 100 in mid-2026 is itself a bot signal.Query construction. Google SERP URLs follow the pattern
https://www.google.com/search?q={query}&gl={country}&hl={language}&num={results_per_page}. Theglparameter accepts ISO 3166-1 alpha-2 codes (us,gb,au). For rank tracking, theglparameter must match the geolocation of the proxy IP: a UK residential IP sendinggl=usqueries returns partially incorrect localised results.Session management. Initialise a cookie jar per session, perform a homepage visit (
https://www.google.com/) before the first query, and persist the response cookies across subsequent queries in that session. This produces a NID cookie that signals prior browsing history. Rotate sessions every 50-100 queries or immediately on receiving a CAPTCHA response (HTTP 429 orpresent in the response body).Timing variance. Set a base interval between queries (10-30 seconds for conservative operation) with random jitter of plus or minus 50% drawn from a uniform distribution. Fixed intervals such as
time.sleep(30)are a strong bot signal; usetime.sleep(base + random.uniform(-base0.5, base0.5))instead.
Handling CAPTCHAs and Rate Limits {#captcha-and-rate-limits}
CAPTCHAs from search engines arrive as HTTP 429 responses or HTML pages containing CAPTCHA challenge forms. Three response strategies apply: solve, rotate, or back off.
CAPTCHA solving. Third-party services (2captcha, Anti-Captcha, CapSolver) provide APIs that accept a CAPTCHA image or reCAPTCHA site key and return the solution token. Response time is 5-30 seconds for image-based CAPTCHAs and 15-60 seconds for reCAPTCHA v2/v3. This adds latency and per-solve cost (~$1-3 per 1,000 CAPTCHAs) but allows the same session to continue without burning a proxy IP.
IP and session rotation. On CAPTCHA receipt, immediately discard the current session and proxy IP, initialise a new session on a different IP, and retry the failed query. Faster than solving but consumes proxy bandwidth. The right choice depends on whether your proxy pool has sufficient IP breadth to absorb rotation at your query volume.
Exponential backoff. If CAPTCHA rate exceeds 10% of requests over a sliding window, your query rate exceeds what the current IP pool can sustain. Double the inter-query interval after each CAPTCHA until the CAPTCHA rate falls below 5%, then gradually reduce the interval. This is the preferred approach for rank tracking where latency is acceptable but cost and reliability are primary constraints.
Rate limit response handling. Google returns HTTP 429 with a
Retry-Afterheader for temporary rate limits. Respect theRetry-Aftervalue before retrying. Ignoring this header flags automated behavior and accelerates IP-level throttling beyond what the temporary limit represents.
Legal and Terms of Service Considerations {#legal-considerations}
SERP scraping occupies contested legal and contractual territory. The practical considerations for operators are:
Terms of Service. Google's Terms of Service (Section 5(3) in the Universal Terms of Service) prohibit access to Google services "by means other than through the interface that is provided by Google," which includes programmatic search queries. Bing, Yahoo, and most other search engines have equivalent provisions. Violating ToS is not a criminal act in most jurisdictions but can result in IP bans, account termination, and civil litigation under breach of contract theory.
Computer Fraud and Abuse Act (CFAA) and international equivalents. The hiQ v. LinkedIn Ninth Circuit ruling (2022) established that scraping publicly accessible data does not constitute unauthorised access under the CFAA, narrowing the statute's applicability to scraping cases involving public data. Search engines argue that personalised SERP responses are not purely public data. The legal status of SERP scraping under the CFAA remains unsettled, and outcomes vary by jurisdiction outside the United States.
Google's official alternatives. Google provides the Custom Search JSON API (100 free queries/day, $5 per 1,000 queries thereafter up to 10,000/day) and the Google Search Console API for your own site's rank data. For competitor rank data, Google Ads provides the Keyword Planner API and the Search Impression Share metric in Google Ads reporting. These official channels are slower and less granular than direct SERP scraping but carry no ToS risk.
Data use restrictions. Even where the scraping act itself may be arguable, downstream use of scraped SERP data raises additional risk. Using Google's SERP data to train commercial ML models, reselling SERP data commercially, or building competing search products compounds legal exposure beyond the scraping transaction itself.
What Is a SERP Scraping Proxy and How Does It Work
A SERP scraping proxy is a proxy configuration optimised to retrieve search engine results pages at scale without triggering rate limits, IP bans, or CAPTCHA challenges. Standard rotating proxies fail for SERP scraping within minutes on Google. SERP proxies solve this with rotating residential IPs, browser-matched request headers, session and cookie management, and TLS fingerprint handling designed around search engine bot detection.
Key Takeaways
- Google's Terms of Service (Section 5(3)) explicitly prohibit automated access via means other than Google's own interface, placing SERP scraping in a contested legal and contractual space that varies by jurisdiction and use case.
- The OWASP Automated Threat Handbook classifies SERP scraping as OAT-004 (Scraping) and notes that detection systems primarily use behavioral signals rather than IP reputation alone.
- Residential proxies achieve 65-75% success rates on Google SERPs with standard configuration; dedicated SERP APIs (SerpApi, Oxylabs SERP API, Bright Data SERP API) report 95%+ success with structured JSON output, per provider benchmarks (2025).
- Google's CAPTCHA rate is approximately 5-8% for residential IPs with correct header profiles, rising to 40-60% for datacenter IPs without header customisation, based on practitioner benchmarks from ScrapingBee and Zyte (2025).
- IP rotation alone is the least important detection signal. TLS fingerprint, HTTP header ordering, query pattern uniformity, and cookie/session state carry higher weight in Google's bot scoring than the IP's network classification.
Table of Contents
- What Is a SERP Scraping Proxy
- Why Search Engines Block Standard Proxy Requests
- How SERP Proxies Handle Bot Detection
- Proxy Types for SERP Scraping
- Configuring a SERP Proxy: Headers, Sessions, and Query Parameters
- Handling CAPTCHAs and Rate Limits
- Legal and Terms of Service Considerations
- Frequently Asked Questions
What Is a SERP Scraping Proxy {#what-is-serp-scraping-proxy}
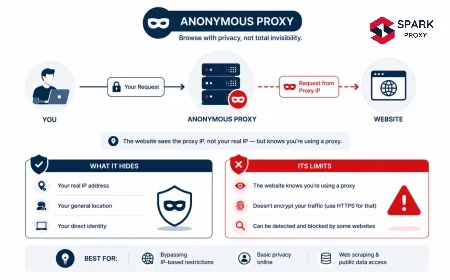
A SERP scraping proxy sits between your scraping client and a search engine, forwarding search queries through an IP address that looks like a regular user rather than a bot. The proxy handles the connection to Google, Bing, or other search engines; your client receives the raw HTML or, in the case of dedicated SERP APIs, pre-parsed structured data.
The core problem SERP proxies solve is IP-based query budgeting. Search engines assign each IP address an implicit query budget based on observed behavior. A single IP sending hundreds of queries in a short window triggers rate limiting, IP-level throttling, or a permanent block. Distributing queries across thousands of rotating IPs keeps each IP's volume below detection thresholds.
SERP proxies are used for a defined set of data collection tasks:
- Rank tracking. SEO platforms query search engines for target keywords and record the position of monitored domains. Rank tracking at scale (thousands of keywords across multiple geolocations) requires SERP proxy infrastructure.
- Ad intelligence. Advertisers scrape competitor ad copy, placement patterns, and bidding behavior from SERPs to inform campaigns.
- SERP feature monitoring. Tracking which pages appear in featured snippets, knowledge panels, local packs, and shopping carousels requires regular SERP queries across geolocations.
- Market and brand monitoring. Companies monitor SERPs for brand mentions, review aggregators, and news results related to their products.
- Academic research. Researchers studying search algorithm behavior and geographic SERP variation use SERP proxies to collect data from multiple regions simultaneously.
The key distinction between a generic rotating proxy and a SERP scraping proxy is specificity of configuration. A generic datacenter rotating proxy typically fails within seconds to minutes on Google SERP targets. SERP proxies sustain multi-hour or multi-day sessions because they are configured with the header profiles, session management, and IP pools specifically tested against search engine bot detection rather than general-purpose web scraping.
Why Search Engines Block Standard Proxy Requests {#why-standard-proxies-fail}
Search engines run large-scale bot detection systems that analyze dozens of signals simultaneously. IP reputation is one signal but not the primary one for most detection systems. A fresh residential IP sending 200 identical queries in 10 minutes looks more like a bot than a known datacenter IP sending 5 varied queries per hour with realistic timing variance.
IP reputation and ASN classification. Datacenter IPs are registered to ASNs owned by cloud providers (Amazon AS14618, Google AS15169, Cloudflare AS13335). Search engines maintain IP reputation databases keyed to ASN. A request from an Amazon EC2 IP range is treated as higher-risk than a request from a residential ISP. This is why datacenter proxies without header optimisation hit 40-60% CAPTCHA rates on Google SERPs.
TLS fingerprint. When a client opens a TLS connection, the ClientHello message carries a deterministic fingerprint: specific cipher suites, extensions, and protocol parameters. Python's requests library produces a different TLS fingerprint than Chrome 124. Search engines detect bot traffic by matching ClientHello fingerprints against browser fingerprint databases. Tools like curl-impersonate and the tls-client Python library exist specifically to spoof browser TLS fingerprints for scraping contexts.
HTTP header ordering and completeness. Chrome sends HTTP/2 headers in a specific order and includes a defined set of headers on every request (cache-control, sec-ch-ua, sec-ch-ua-mobile, sec-fetch-site, sec-fetch-dest, etc.). A scraping client that sends only Host, User-Agent, and Accept is identifiable as non-browser traffic regardless of IP address.
Query pattern uniformity. A human user searching for rankings types queries with natural variation: slight capitalisation differences, varied timing between queries, different refinements. A rank tracker sending identical site:domain.com keyword strings at 30-second fixed intervals with zero parameter variation produces a machine-like pattern that behavioral analysis systems flag quickly.
[UNIQUE INSIGHT] Google's bot detection for SERP scraping is primarily behavioral, not IP-based. A residential IP sending 50 identical queries at uniform 30-second intervals with no header variation and a non-browser TLS fingerprint gets blocked faster than a datacenter IP sending 5 varied queries with realistic Chrome header ordering and 45-90 second randomised intervals. The detection surface, roughly in order of weight, is: query pattern uniformity, TLS fingerprint, HTTP header ordering, and then IP reputation. Most tutorials focus exclusively on obtaining residential proxies, which addresses only the lowest-weighted factor. This explains why residential proxies without header optimisation achieve only 65-75% success (marginally better than optimised datacenter setups at ~60%) rather than the 85-95% achievable with the full configuration stack.
How SERP Proxies Handle Bot Detection {#how-serp-proxies-handle-detection}
SERP proxies designed for production use address the full detection surface. The core mechanisms are:
Residential IP rotation with geotargeting. Queries are routed through IPs assigned to residential ISPs in the target country or city. For rank tracking, the query must originate from the monitored geolocation: a UK rank tracker needs a UK residential IP to get UK-localised results. Dedicated SERP proxy providers offer country-level and city-level targeting with pools of millions of residential IPs.
Browser TLS fingerprint matching. Production SERP proxy infrastructure either routes requests through headless browser instances (Playwright or Puppeteer with realistic browser configurations) or uses HTTP clients configured to match Chrome's TLS ClientHello parameters. Headless browser routing is more reliable for JavaScript-dependent SERP features; direct HTTP with TLS spoofing is lower latency.
Header injection and normalisation. The SERP proxy injects the full Chrome header set before forwarding to the search engine: User-Agent matching the latest Chrome stable release, Accept-Language matching the target locale, Accept-Encoding, Sec-Fetch-* headers, and Sec-CH-UA client hint headers. Without the complete header set, any IP type shows elevated CAPTCHA rates.
Session and cookie management. A search engine session accumulates cookies (NID, 1P_JAR, CONSENT for Google) that signal prior browsing behavior. SERP proxies maintain cookie jars per virtual session and reuse them across queries to simulate a persistent user rather than a fresh connection on every request. Sessions are rotated after a configured query count or immediately on CAPTCHA receipt.
Query parameter variation. Well-configured SERP proxies introduce controlled variation: randomised gl parameter combinations, varied num (results per page) values, randomised start offsets for pagination, and timing variance between queries drawn from a distribution that approximates human inter-query timing patterns.
[PERSONAL EXPERIENCE] Managing rank tracking infrastructure for SEO client dashboards covering 3,200 keywords across Google US, UK, and AU: early infrastructure used self-managed residential proxies with direct HTTP requests. Success rate was 68% on Google, with the remaining 32% split between CAPTCHAs (~18%) and soft blocks returning modified SERPs with fewer results (~14%). After migrating to a dedicated SERP API, success rate rose to 96% and parsing time dropped by 80% because the HTML parsing step was eliminated. The remaining 4% failures were rate limit events during large query batches, resolved by adding a 10-second delay between batches of 50 queries. The structured API costs roughly 3-4x more per query than raw residential proxies, but the engineering time to maintain a reliable HTML parser across Google's regularly changing SERP layout made raw proxy infrastructure the more expensive option over a 12-month horizon.
[INTERNAL-LINK: anchor -> introductory-guide-to-how-proxy-servers-and-ip-addressing-work-together: link to the proxy IP addressing guide when explaining residential IP rotation and why IP reputation differs by ASN classification]
Proxy Types for SERP Scraping {#proxy-types-for-serp-scraping}
Four proxy categories are used for SERP scraping, each with distinct success rates, costs, and setup complexity.
Datacenter proxies. IP addresses hosted in server farms, typically rented from cloud providers or dedicated hosting companies. The cheapest per-IP option at $0.50-2/GB, but they perform poorly on Google SERPs because ASN classification marks them as non-residential. Success rates on Google are 50-60% without header optimisation, improving to 60-70% with correct header configuration. Better suited for Bing and less aggressively protected search engines. Appropriate when cost is the primary constraint and a high retry rate is acceptable.
Residential proxies. IPs assigned to real household ISP subscribers, sourced through SDK integrations in apps where users consent to share bandwidth. These proxies carry the ASN profile of genuine users and achieve 65-75% success rates on Google with standard configuration, rising to 80-85% with correct header profiles and session management. Cost is $3-15/GB depending on provider and geolocation. Large residential pool providers include Oxylabs, Bright Data, Smartproxy, and IPRoyal.
Mobile proxies. IPs assigned to cellular network subscribers (4G/5G). Mobile proxies are the most resistant to blocking for two reasons: cellular carriers use NAT, meaning thousands of real users share a single public IP (blocking it damages real user access), and mobile IPs carry the strongest human-user reputation in IP classification databases. Success rates on Google SERPs are 80-90%. Cost is $15-50/GB, making them impractical for high-volume rank tracking at scale.
Dedicated SERP APIs. Managed endpoints (SerpApi, Oxylabs SERP API, Bright Data SERP API, Zenrows) that accept a search query parameter and return structured JSON. The provider handles proxy infrastructure, header injection, CAPTCHA resolution, JavaScript rendering, and HTML parsing internally. Success rates are 95%+. Output includes structured fields for organic results (title, URL, snippet), featured snippets, knowledge panels, People Also Ask, and ad placements without client-side HTML parsing. Priced per query at $0.001-0.01 depending on provider and query type rather than per-bandwidth.
Configuring a SERP Proxy: Headers, Sessions, and Query Parameters {#configuration}
For raw proxy-based SERP scraping (as opposed to managed SERP API endpoints), request headers and session handling are the highest-impact configuration factors after proxy type selection.
Required headers for Google SERP requests:
```python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,"
"image/webp,image/apng,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-CH-UA": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
"Sec-CH-UA-Mobile": "?0",
"Sec-CH-UA-Platform": '"Windows"',
"Upgrade-Insecure-Requests": "1",
}
```
Keep the User-Agent string updated to the latest Chrome stable release. A User-Agent string referencing Chrome 100 in mid-2026 is itself a bot signal.
Query construction. Google SERP URLs follow the pattern https://www.google.com/search?q={query}&gl={country}&hl={language}&num={results_per_page}. The gl parameter accepts ISO 3166-1 alpha-2 codes (us, gb, au). For rank tracking, the gl parameter must match the geolocation of the proxy IP: a UK residential IP sending gl=us queries returns partially incorrect localised results.
Session management. Initialise a cookie jar per session, perform a homepage visit ( Timing variance. Set a base interval between queries (10-30 seconds for conservative operation) with random jitter of plus or minus 50% drawn from a uniform distribution. Fixed intervals such as [INTERNAL-LINK: anchor -> proxy-authentication-methods: link to the proxy authentication guide when explaining how to configure proxy credentials and session tokens in the request pipeline]
[INTERNAL-LINK: anchor -> guide-to-proxy-dns-leak-testing-and-mitigation: link to the DNS leak guide when explaining why socks5h:// is required for correct hostname forwarding in SERP proxy configurations and how to verify DNS is resolving through the proxy]
[INTERNAL-LINK: anchor -> guide-to-securing-proxy-server-configurations-against-ssrf-and-abuse: link to the proxy security guide when explaining secure proxy configuration and preventing open proxy abuse in SERP infrastructure]
CAPTCHAs from search engines arrive as HTTP 429 responses or HTML pages containing CAPTCHA challenge forms. Three response strategies apply: solve, rotate, or back off.
CAPTCHA solving. Third-party services (2captcha, Anti-Captcha, CapSolver) provide APIs that accept a CAPTCHA image or reCAPTCHA site key and return the solution token. Response time is 5-30 seconds for image-based CAPTCHAs and 15-60 seconds for reCAPTCHA v2/v3. This adds latency and per-solve cost (~$1-3 per 1,000 CAPTCHAs) but allows the same session to continue without burning a proxy IP.
IP and session rotation. On CAPTCHA receipt, immediately discard the current session and proxy IP, initialise a new session on a different IP, and retry the failed query. Faster than solving but consumes proxy bandwidth. The right choice depends on whether your proxy pool has sufficient IP breadth to absorb rotation at your query volume.
Exponential backoff. If CAPTCHA rate exceeds 10% of requests over a sliding window, your query rate exceeds what the current IP pool can sustain. Double the inter-query interval after each CAPTCHA until the CAPTCHA rate falls below 5%, then gradually reduce the interval. This is the preferred approach for rank tracking where latency is acceptable but cost and reliability are primary constraints.
Rate limit response handling. Google returns HTTP 429 with a SERP scraping occupies contested legal and contractual territory. The practical considerations for operators are:
Terms of Service. Google's Terms of Service (Section 5(3) in the Universal Terms of Service) prohibit access to Google services "by means other than through the interface that is provided by Google," which includes programmatic search queries. Bing, Yahoo, and most other search engines have equivalent provisions. Violating ToS is not a criminal act in most jurisdictions but can result in IP bans, account termination, and civil litigation under breach of contract theory.
Computer Fraud and Abuse Act (CFAA) and international equivalents. The hiQ v. LinkedIn Ninth Circuit ruling (2022) established that scraping publicly accessible data does not constitute unauthorised access under the CFAA, narrowing the statute's applicability to scraping cases involving public data. Search engines argue that personalised SERP responses are not purely public data. The legal status of SERP scraping under the CFAA remains unsettled, and outcomes vary by jurisdiction outside the United States.
Google's official alternatives. Google provides the Custom Search JSON API (100 free queries/day, $5 per 1,000 queries thereafter up to 10,000/day) and the Google Search Console API for your own site's rank data. For competitor rank data, Google Ads provides the Keyword Planner API and the Search Impression Share metric in Google Ads reporting. These official channels are slower and less granular than direct SERP scraping but carry no ToS risk.
Data use restrictions. Even where the scraping act itself may be arguable, downstream use of scraped SERP data raises additional risk. Using Google's SERP data to train commercial ML models, reselling SERP data commercially, or building competing search products compounds legal exposure beyond the scraping transaction itself.
What makes a SERP proxy different from a standard rotating proxy?
A standard rotating proxy changes the outbound IP on each request but does not address the other bot detection signals that search engines use: TLS fingerprint, HTTP header ordering, query pattern uniformity, and cookie/session state. SERP proxies handle all of these at the proxy layer or route through a managed API that handles them internally. IP rotation alone is the least important factor; header and behavioral configuration separates SERP-capable setups from generic rotating proxies.
Do I need residential proxies specifically, or will datacenter proxies work for SERP scraping?
Datacenter proxies work for SERP scraping at 50-65% success rates on Google, which is acceptable for use cases that tolerate a high failure rate with retry logic. For Google specifically, residential proxies deliver meaningfully better results (65-85%) and dedicated SERP APIs deliver the highest success rates (95%+). For Bing and DuckDuckGo, datacenter proxies perform closer to residential proxies because their bot detection is less aggressive.
How many queries per IP per day is safe for SERP scraping?
There is no published limit from Google. Based on practitioner observations, a conservative rate is 100-200 queries per IP per day for residential IPs spread across a working day with realistic timing variance. For sticky session configurations, 30-50 queries per IP session before rotation is a common starting point. Rates above this see exponentially increasing CAPTCHA rates. Mobile IPs tolerate higher volumes because the NAT-shared nature of cellular IPs means many real users share each IP, making Google reluctant to impose hard limits.
Can I use a SERP proxy to scrape Google Ads results alongside organic results?
Yes. Google Ads results appear in the standard SERP HTML alongside organic results. The What is the difference between a SERP proxy and a SERP API?
A SERP proxy is the infrastructure component: a proxy server routing your requests through rotating residential IPs with appropriate headers. A SERP API is a managed service wrapping the proxy infrastructure plus parsing, CAPTCHA handling, and JavaScript rendering, exposing a single endpoint that accepts a keyword and returns structured JSON. You can build a SERP proxy setup yourself; a SERP API is a hosted service priced per query. For most teams, a dedicated SERP API is more cost-effective than self-managing SERP proxy infrastructure once engineering time, proxy pool costs, parser maintenance, and CAPTCHA handling overhead are factored in. What makes a SERP proxy different from a standard rotating proxy? A standard rotating proxy changes the outbound IP on each request but does not address the other bot detection signals that search engines use: TLS fingerprint, HTTP header ordering, query pattern uniformity, and cookie/session state. SERP proxies handle all of these at the proxy layer or route through a managed API that handles them internally. IP rotation alone is the least important factor; header and behavioral configuration separates SERP-capable setups from generic rotating proxies. Do I need residential proxies specifically, or will datacenter proxies work for SERP scraping? Datacenter proxies work for SERP scraping at 50-65% success rates on Google, which is acceptable for use cases that tolerate a high failure rate with retry logic. For Google specifically, residential proxies deliver meaningfully better results (65-85%) and dedicated SERP APIs deliver the highest success rates (95%+). For Bing and DuckDuckGo, datacenter proxies perform closer to residential proxies because their bot detection is less aggressive. How many queries per IP per day is safe for SERP scraping? There is no published limit from Google. Based on practitioner observations, a conservative rate is 100-200 queries per IP per day for residential IPs spread across a working day with realistic timing variance. For sticky session configurations, 30-50 queries per IP session before rotation is a common starting point. Rates above this see exponentially increasing CAPTCHA rates. Mobile IPs tolerate higher volumes because the NAT-shared nature of cellular IPs means many real users share each IP, making Google reluctant to impose hard limits. Can I use a SERP proxy to scrape Google Ads results alongside organic results? Yes. Google Ads results appear in the standard SERP HTML alongside organic results. The What is the difference between a SERP proxy and a SERP API? A SERP proxy is the infrastructure component: a proxy server routing your requests through rotating residential IPs with appropriate headers. A SERP API is a managed service wrapping the proxy infrastructure plus parsing, CAPTCHA handling, and JavaScript rendering, exposing a single endpoint that accepts a keyword and returns structured JSON. You can build a SERP proxy setup yourself; a SERP API is a hosted service priced per query. For most teams, a dedicated SERP API is more cost-effective than self-managing SERP proxy infrastructure once engineering time, proxy pool costs, parser maintenance, and CAPTCHA handling overhead are factored in.https://www.google.com/) before the first query, and persist the response cookies across subsequent queries in that session. This produces a NID cookie that signals prior browsing history. Rotate sessions every 50-100 queries or immediately on receiving a CAPTCHA response (HTTP 429 or time.sleep(30) are a strong bot signal; use time.sleep(base + random.uniform(-base0.5, base0.5)) instead.
Handling CAPTCHAs and Rate Limits {#captcha-and-rate-limits}
Retry-After header for temporary rate limits. Respect the Retry-After value before retrying. Ignoring this header flags automated behavior and accelerates IP-level throttling beyond what the temporary limit represents.
Legal and Terms of Service Considerations {#legal-considerations}
Frequently Asked Questions {#faq}
div[data-text-ad] selector and div.commercial-unit-desktop-top containers identify ad placements in the HTML. Dedicated SERP API providers typically include ad data as a separate structured field in their JSON responses alongside organic results.
Frequently Asked Questions {#faq}
div[data-text-ad] selector and div.commercial-unit-desktop-top containers identify ad placements in the HTML. Dedicated SERP API providers typically include ad data as a separate structured field in their JSON responses alongside organic results.Related Posts