





What Is a Web Scraping Proxy? How It Works, Types & Best Practices (2026)
A web scraping proxy rotates your IP address so scrapers collect data without bans. Residential proxies hit 94% success rates vs 23% for datacenter. Full guide inside.
-
What Is a Web Scraping Proxy?
Without a proxy, even a well-written web scraper typically gets blocked within minutes of starting on any site with modern bot defenses. Anti-bot systems from Cloudflare, Akamai, and PerimeterX track your IP address — and once your query rate looks inhuman, they block you. A web scraping proxy solves this by routing each request through a different IP address, making your scraper look like a stream of ordinary users rather than a single bot. The global web scraping market is on track to reach $6.8 billion by 2028 (MarketsandMarkets, 2024), and proxy infrastructure is the foundational layer underneath virtually all of it.
Key Takeaways- A web scraping proxy routes requests through rotating IP addresses to avoid rate-limiting and IP bans during data collection.
- Residential proxies achieve 89–97% success rates on heavily protected targets like Google and Amazon vs. 20–30% for datacenter IPs (Bright Data, 2024).
- The four main proxy types — residential, mobile, ISP (static residential), and datacenter — trade off cost vs. success rate. The right choice depends on your target site's anti-bot tier.
- Python setup takes under 10 lines; enterprise-grade operations use provider SDKs with built-in rotation, CAPTCHA solving, and session management.
- Over 43% of all internet traffic is now automated — anti-bot systems are increasingly sophisticated, making proxy quality the single biggest variable in scraping success (Imperva Bad Bot Report, 2025).
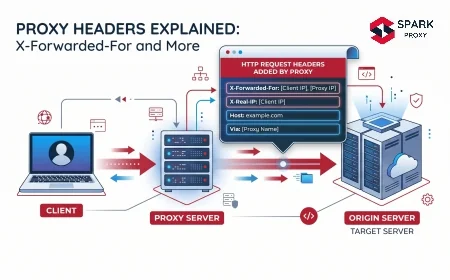
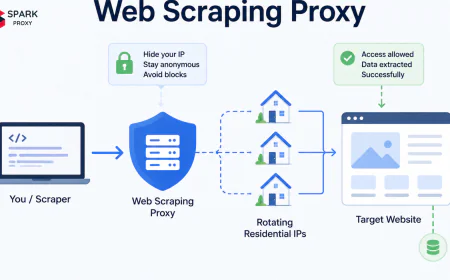
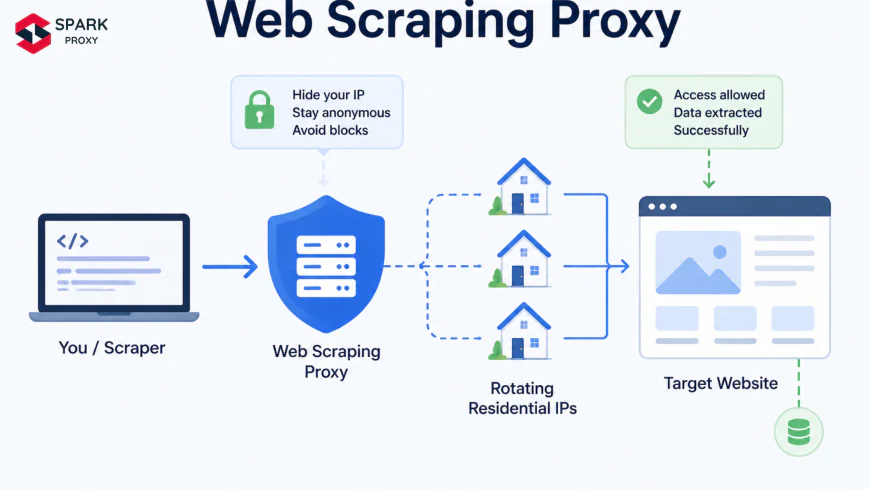
A web scraping proxy is an intermediary server that sits between your scraping client and the target website, forwarding your HTTP requests from a different IP address. Instead of your scraper's real IP appearing in the server logs, the target site sees the proxy's IP — and with a rotating proxy pool, each request appears to originate from a different address entirely.
The mechanics are straightforward:
Your scraper → Proxy server (new IP per request) → Target website → Response → Your scraperWhat makes a proxy specifically useful for scraping — rather than just general privacy — is that scraping proxies are engineered around three distinct problems that standard proxies don't address:
- IP rotation at scale — pools of thousands to millions of IPs that cycle automatically.
- Session management — maintaining the same IP across a multi-page session when needed ("sticky sessions").
- Anti-fingerprinting — injecting realistic browser headers, managing TLS fingerprints, and handling CAPTCHAs invisibly.
Without all three, a proxy is just a privacy tool. With them, it becomes scraping infrastructure.
-
How Does a Web Scraping Proxy Work?
When your scraping code sends a request through a rotating proxy, four technical layers activate in sequence. Each layer addresses a specific detection vector that anti-bot systems monitor.
-
1. IP Assignment and Rotation
The proxy provider's network manager assigns a source IP from its pool and attaches it to your outbound request. In auto-rotate mode, every request uses a new IP. In sticky-session mode, the same IP is held for a configurable window (typically 1–30 minutes) — useful when scraping paginated content where abrupt IP changes signal bot activity.
-
2. Header Injection
Quality scraping proxies inject — or let you specify — realistic HTTP headers:
User-Agent,Accept-Language,Accept-Encoding,Referer, andsec-ch-uaclient hints. A request arriving with a correctly structured header set is dramatically harder to fingerprint than one with defaultpython-requests/2.xheaders. -
3. TLS Fingerprint Normalization
Advanced anti-bot systems like Cloudflare inspect the TLS handshake's JA3 hash — a fingerprint of which cipher suites and extensions your client supports. A Python
requestscall has a distinctive JA3 hash that differs from Chrome. Enterprise-tier proxy providers normalize this fingerprint to match common browsers, eliminating one of the most reliable bot-detection signals. -
4. CAPTCHA Handling
When a CAPTCHA checkpoint fires, the proxy either automatically retries via a clean IP or routes the request through an integrated solving service (2captcha, Anti-Captcha, or a proprietary solver). This happens between the proxy network and your code — your scraper receives a successful response without needing CAPTCHA-handling logic.
Proxy success rate on Google and Amazon, 2024 — Source: Bright Data Proxy Research
-
-
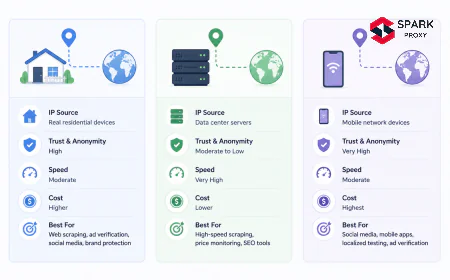
What Types of Web Scraping Proxies Are There?
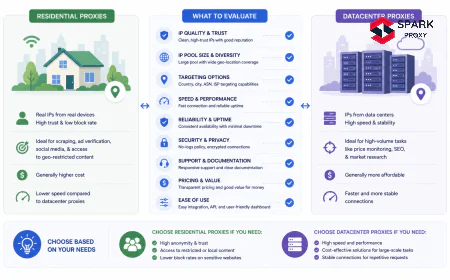
Choosing the wrong proxy type is the most common — and most expensive — mistake in scraping infrastructure. Here is how each type performs, and when to use it.
Different proxy types route traffic differently — residential, mobile, ISP, and datacenter each carry distinct tradeoffs. Proxy Type Success Rate* Cost ($/GB) Best For Mobile ~97% $15–$40 Mission-critical pipelines, carrier-NAT environments Residential ~94% $2–$15 Google, Amazon, social networks, geo-targeted scraping ISP (Static Residential) ~71% $3–$8 Long sessions, authenticated scraping, moderate volumes Datacenter ~23% $0.50–$2 Bing/DuckDuckGo, low-protection sites, high-speed bulk jobs * Success rate on heavily protected targets (Google, Amazon). Performance on lighter targets is significantly higher for all types.
-
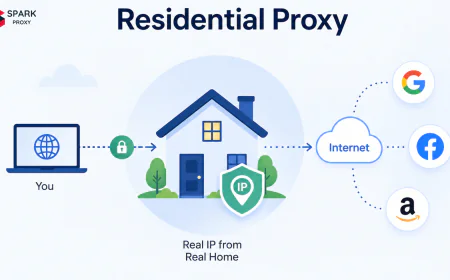
Residential Proxies
IPs assigned by ISPs to real home devices. Search engines and e-commerce sites have no reliable way to identify residential IPs as bots — blocking them risks blocking genuine customers on the same ISP range. The largest providers (Bright Data, Oxylabs, Smartproxy) maintain pools of 70M+ residential IPs globally. Cost: $2–$15/GB.
→ See also: What Is a Residential Proxy? Complete Guide
-
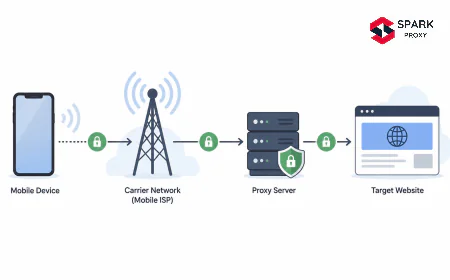
Mobile Proxies
IPs assigned to mobile devices on 3G/4G/5G networks. Because mobile carriers use NAT (many users share one IP), blocking a mobile IP would disconnect dozens of legitimate subscribers. This makes mobile proxies almost unblockable. Success rate: ~97%. The trade-off is cost ($15–$40/GB) — deploy mobile proxies only where success rate is worth the premium.
-
ISP (Static Residential) Proxies
Datacenter hardware registered to ISP ASNs, giving them residential-looking WHOIS records. Faster than true residential proxies (dedicated bandwidth, no peer routing), and they support sticky sessions indefinitely. Good middle ground for teams that need session stability at lower cost than mobile.
-
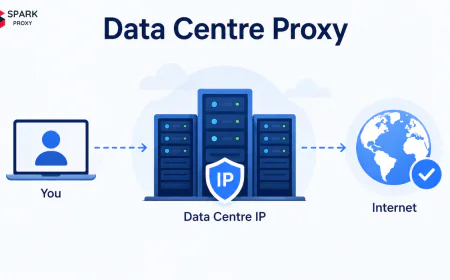
Datacenter Proxies
IPs from commercial cloud providers (AWS, OVH, Hetzner). Fast, cheap ($0.50–$2/GB), and easy to scale — but anti-bot systems have catalogued entire datacenter ASN ranges. On Google or Amazon, expect 77%+ of requests to be blocked (Imperva, 2025). Still the right choice for lower-protection targets or non-Google engines (Bing, DuckDuckGo, Yahoo).
→ See also: What Is a Datacenter Proxy? Speed, Cost & Use Cases
-
-
What Are the Main Use Cases for Web Scraping Proxies?
The web scraping market is projected to grow at a CAGR of 14.2% through 2028, driven by business intelligence demand that maps almost exactly onto proxy use cases (MarketsandMarkets, 2024). The five most common applications are:
Web scraping proxy use cases by share of market demand — Source: Oxylabs Proxy Usage Research, 2025 -
Price Intelligence & E-Commerce Monitoring (28%)
Retailers scrape competitor pricing, product availability, and promotional data to feed dynamic repricing algorithms. Amazon, Walmart, and major retail sites deploy aggressive anti-bot systems specifically to prevent this — making residential proxies the only viable choice for high-volume retail scraping.
-
SERP & SEO Data Collection (24%)
Rank trackers, keyword research tools, and SERP monitoring services check thousands of keywords daily across multiple geographies. The average enterprise SEO team monitors 1,200+ keywords per day (Semrush State of Search, 2025), each requiring a geo-targeted proxy request to return location-accurate results.
→ See also: What Is a SERP Scraping Proxy? Complete Guide
-
Social Media Scraping (19%)
Brand monitoring, influencer analytics, and sentiment analysis tools collect public social media data at scale. Platforms like X (Twitter), Instagram, and LinkedIn maintain some of the most aggressive anti-bot systems on the web — mobile proxies are typically required to sustain reliable collection.
-
Travel & Fare Aggregation (15%)
Flight, hotel, and car rental aggregators scrape availability and pricing from supplier sites in near-real-time. Airlines use sophisticated bot detection that fingerprints requests down to the JavaScript rendering engine, making headless browser proxies with full fingerprint spoofing necessary for this use case.
-
-
How to Set Up a Web Scraping Proxy
A basic proxy setup in Python takes under 10 lines — enterprise configurations add rotation, retry logic, and session management. -
Basic Setup in Python (requests library)
import requests import random # Proxy pool — replace with your provider's credentials and endpoints PROXY_POOL = [ "http://user:[email protected]:10000", "http://user:[email protected]:10001", "http://user:[email protected]:10002", ] def scrape(url): proxy = random.choice(PROXY_POOL) proxies = {"http": proxy, "https": proxy} headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36", "Accept-Language": "en-US,en;q=0.9", } response = requests.get(url, proxies=proxies, headers=headers, timeout=15) response.raise_for_status() return response.textFor production workloads, replace the manual pool with a provider SDK. Bright Data, Oxylabs, and Smartproxy all provide Python SDKs that handle rotation, sticky sessions, CAPTCHA solving, and retry logic automatically — reducing 300+ lines of proxy management code to a single configuration object.
-
Key Configuration Parameters
- Session type — use
rotatingfor independent requests,stickyfor paginated content (set session duration ≥ 10 minutes). - Geo-targeting — specify country, state, or city for location-sensitive data (SERP, local pricing, regional availability).
- Request timeout — residential proxies add 200–800ms latency vs. datacenter. Set timeout to 15–30s to avoid premature failures.
- Retry logic — retry on 403/429 with exponential backoff plus IP rotation. Never retry the same IP on a block.
- Concurrency — rate-limit to 1 request/IP/60s on protected targets. Higher concurrency requires proportionally more IPs, not fewer.
- Session type — use
-
-
How to Choose a Web Scraping Proxy Provider
The proxy market has consolidated around a handful of enterprise providers — but 62% of buyers still prioritize success rate over cost when selecting a provider for high-value targets (Oxylabs Research, 2025). Evaluate providers across six dimensions:
- IP pool size and geo-coverage — verify density in your specific target markets, not just total IPs. A provider with 70M IPs concentrated in North America may underserve Southeast Asian targets.
- Sticky session duration — minimum 10 minutes for paginated scraping. Some providers cap at 1–5 minutes, which breaks multi-page workflows.
- CAPTCHA handling — built-in solver (included in price) vs. pass-through (you pay extra per solve). Built-in is operationally simpler; compare total cost per successful request.
- Pricing model — traffic-based ($/GB) for variable workloads; request-based ($/1K requests) for fixed-volume operations. Reject providers that charge for blocked/failed requests.
- JavaScript rendering — if your target loads critical content via JS (React SPAs, lazy-loaded prices), the proxy must support a headless browser mode or rendering layer.
- Ethical IP sourcing — residential IPs must be sourced with explicit user consent (opt-in apps, VPN extensions). Ask for the provider's consent model documentation — your legal exposure depends on it.
Ready to build your first scraping pipeline? Our proxy setup tutorial walks through authentication, rotation, and session configuration for the top three providers — with tested Python code for each.
Read the Setup Tutorial → -
Conclusion
A web scraping proxy is the infrastructure layer that makes automated data collection viable at scale. Without it, any meaningful scraping operation hits rate limits and IP bans within minutes. With the right proxy type — residential or mobile for protected targets, datacenter or ISP for everything else — success rates rise to 94–97% and the core scraping problem shifts from "how do I avoid blocks?" to "how do I parse this data efficiently?".
The practical hierarchy is simple: match proxy type to target protection level, use sticky sessions for paginated content, and never retry a blocked IP. For teams without scraping engineering bandwidth, a managed proxy provider with built-in CAPTCHA solving and session management reduces weeks of infrastructure work to a single API call.
→ Compare the top proxy providers for web scraping in 2026 →