





What Is Web Scraping? How It Works, Tools & Legal Guide (2026)
Web scraping automates data extraction from websites. 43% of internet traffic is now automated. Learn how it works, which tools to use, and what's legal in 2026.
-
What Is Web Scraping?
Every time a price comparison site shows you the cheapest flight, a hedge fund feeds live stock sentiment into its model, or a job board aggregates listings from 200 sources, web scraping is running underneath. It's the infrastructure of the modern data economy — yet most people who use its outputs have never heard the term. Web scraping is the automated extraction of data from websites, and with 43% of all internet traffic now automated (Imperva Bad Bot Report, 2025), it's one of the most widely deployed technologies in software engineering. This guide explains exactly what it is, how it works at a technical level, which tools to use, and where the legal lines sit in 2026.
Key Takeaways- Web scraping is the automated extraction of structured data from websites using HTTP requests and HTML parsing.
- 43% of all internet traffic is now automated — a large share of it scraping-driven (Imperva, 2025).
- Python dominates: over 70% of scraping projects use requests, BeautifulSoup, or Scrapy (GitHub Octoverse, 2025).
- Public data scraping is generally legal under the 2022 hiQ Labs v. LinkedIn ruling — scraping behind login walls is not.
- The global web data extraction market hits $6.8B by 2028 at 14.2% CAGR (MarketsandMarkets, 2024).
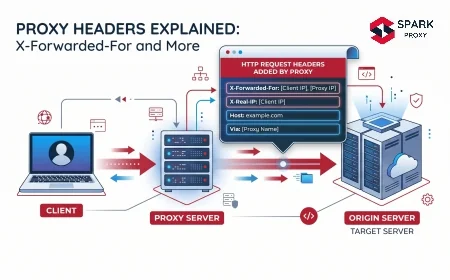
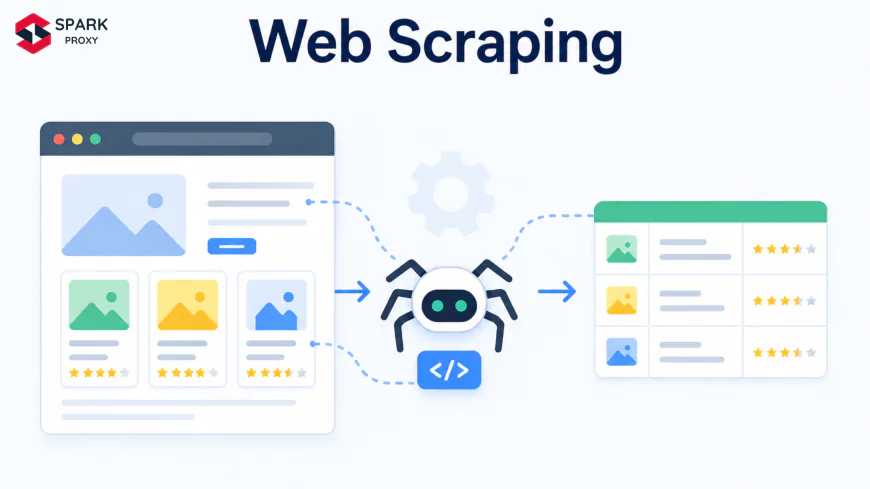
Web scraping (also called data scraping or web harvesting) is the automated process of sending HTTP requests to web pages, receiving the HTML response, and extracting specific data from that HTML using a parser. The result is structured, machine-readable data — a spreadsheet, database, or JSON feed — derived from information that was originally presented as a human-readable web page.
The process differs fundamentally from using a public API. An API gives you data by the provider's design — pre-structured, rate-limited, and requiring explicit permission. Scraping takes publicly visible data regardless of whether an API exists. That distinction matters both technically and legally. When a site doesn't offer an API, scraping is often the only way to access its data programmatically.
Distinction: Web crawling discovers URLs (what search engine bots do). Web scraping extracts data from specific pages. Most scraping pipelines use a crawler to navigate between pages and a scraper to parse each one — but the terms aren't interchangeable.
Web scraping isn't new — early web bots date to the mid-1990s. What changed is scale. Today's scraping infrastructure handles billions of requests daily, powered by cloud computing, rotating proxy networks, and browser automation libraries that can execute JavaScript, solve CAPTCHAs, and mimic human interaction patterns. The global market for web data extraction is projected at $6.8 billion by 2028, growing at 14.2% CAGR (MarketsandMarkets, 2024).
-
How Does Web Scraping Work?
Web scraping pipelines have four layers: HTTP transport, HTML parsing, data extraction, and storage. A web scraper operates in four sequential steps, each with distinct technical requirements. Understanding this pipeline is what separates scrapers that work reliably from ones that break the moment a site updates its layout.
-
Step 1: HTTP Request
The scraper sends an HTTP GET (or POST) request to the target URL. At minimum this includes a
User-Agentheader. Realistic scrapers also sendAccept-Language,Accept-Encoding,Referer, and browser-matchingsec-ch-uaclient hint headers — because anti-bot systems fingerprint the header set as reliably as the IP address. -
Step 2: Receive HTML Response
The server returns HTML (and for dynamic sites, JavaScript that must execute to render the final DOM). Static scrapers parse the raw HTML directly. Dynamic scrapers hand the response to a headless browser that executes the JavaScript and waits for the page to reach a stable state before extracting data.
-
Step 3: Parse and Extract
The HTML is parsed into a tree structure (the DOM). The scraper then uses CSS selectors (
soup.select("div.price")) or XPath expressions (//div[@class="price"]) to locate the specific nodes containing target data. This is the most maintenance-intensive step — when a site redesigns its HTML structure, selectors break and need updating. -
Step 4: Store and Clean
Extracted data is written to a destination: CSV, JSON, PostgreSQL, BigQuery, or a real-time pipeline like Kafka. A cleaning step normalises formats — converting price strings to floats, parsing dates, deduplicating records. Production pipelines add schema validation here to catch extraction failures before corrupt data reaches downstream systems.
# Minimal working scraper — Python + requests + BeautifulSoup import requests from bs4 import BeautifulSoup url = "https://example.com/products" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" } response = requests.get(url, headers=headers, timeout=15) soup = BeautifulSoup(response.text, "html.parser") # Extract all product names and prices for item in soup.select("div.product-card"): name = item.select_one("h2.product-title").text.strip() price = item.select_one("span.price").text.strip() print(f"{name}: {price}")
-
-
What Are the Main Web Scraping Techniques?
Playwright's monthly PyPI downloads grew 340% between 2023 and 2025 (npm/PyPI stats, 2025), a growth curve driven almost entirely by the proliferation of JavaScript-rendered sites that older static scraping tools can't handle. Choosing the wrong technique is the most common reason a scraper fails — here's when to use each one.
-
Static HTML Scraping Fastest
Works when the server sends fully-rendered HTML — no JavaScript execution needed. Use
requests(Python HTTP client) plusBeautifulSouporlxmlfor parsing. This is the simplest, fastest, and cheapest technique. It's still effective on news sites, blogs, government data portals, and many e-commerce product pages. Doesn't work on React/Vue/Angular SPAs where content loads via client-side JavaScript after the initial HTML. -
Headless Browser Scraping For JS-heavy sites
Playwright and Selenium launch a real browser engine (Chromium or Firefox) in headless mode, execute all JavaScript on the page, and expose the rendered DOM. Necessary for SPAs, infinite-scroll feeds, and any site where critical data loads via client-side fetch calls. Slower (3–10× vs. static scraping) and more expensive to run at scale, but the only reliable option for JavaScript-gated content.
-
API Reverse Engineering Most stable
Many modern sites load data via internal REST or GraphQL APIs. By inspecting the browser's Network tab, you can identify the API endpoint (often
/api/v1/products?page=1) and query it directly — getting clean JSON without HTML parsing. This produces more stable scrapers because API schemas change less often than HTML layouts. Works on roughly 40% of modern web apps. -
Browser Extension / Document-Object Injection
For scenarios requiring authenticated sessions (scraping your own CRM, exporting data from SaaS tools with no export feature), injecting JavaScript into a page via a browser extension or via
page.evaluate()in Playwright can extract data already rendered in the DOM without making additional network requests. Useful for single-user automation, not scalable for bulk collection.A practical walkthrough of static scraping with BeautifulSoup — covers HTTP requests, HTML parsing, and data extraction in under 20 minutes:
Python Web Scraping with BeautifulSoup Tutorial — YouTube
-
-
What Tools Do Developers Use for Web Scraping?
The Python scraping ecosystem covers every use case — from quick one-off scripts to production crawlers handling millions of requests per day. BeautifulSoup alone has 65 million monthly PyPI downloads as of early 2026 (PyPI stats, 2025) — making it one of the most-downloaded Python libraries in any category. The ecosystem has clear tiers by use case and complexity.
Source: PyPI Download Stats, January 2025
Library Best For JS Support Skill Level requests + BeautifulSoup Static HTML, quick scripts, learning No Beginner Scrapy Production crawlers, large-scale pipelines, async Middleware only Intermediate Playwright JS-heavy sites, SPAs, modern anti-bot evasion Yes (full) Intermediate Selenium Legacy automation, complex browser interactions Yes (full) Intermediate httpx Async HTTP, API scraping, high-concurrency requests No Intermediate → See also: What Is a Web Scraping Proxy? How It Works, Types & Best Practices
-
What Are the Most Common Web Scraping Use Cases?
73% of data science teams use web scraping as a primary data acquisition method (Kaggle Data Science Survey, 2024), and the use cases span every industry that competes on data speed or coverage.
Source: Oxylabs State of Web Scraping Report, 2025
-
E-Commerce Price Intelligence
The average e-commerce site is scraped 8–12 times per day by competitor intelligence tools (Oxylabs Research, 2024). Retailers use this data to feed dynamic repricing algorithms — Amazon alone runs millions of price adjustments per day, largely informed by scraped competitor data.
-
Financial Data and Market Research
Hedge funds scrape earnings call transcripts, SEC filings, job postings (as a leading economic indicator), and news sentiment at scale. Quant firms treat scraped data as an alternative data source — often giving them a 6–24 hour edge over competitors relying on traditional data vendors.
-
Academic Research and NLP Training Data
Large language models are trained on scraped datasets — CommonCrawl, the Pile, and C4 are all products of web-scale scraping. Academic researchers scrape social media, news archives, and government portals to build datasets for social science, computational linguistics, and public health studies.
A full walkthrough of building a Scrapy spider for production-scale data collection — covers spiders, pipelines, and proxy middleware:
Scrapy Python Tutorial for Beginners — Build a Web Crawler — YouTube
-
-
Is Web Scraping Legal in 2026?
The 2022 hiQ Labs v. LinkedIn ruling by the Ninth Circuit established that scraping publicly accessible websites does not violate the Computer Fraud and Abuse Act (CFAA) — because public data requires no "authorization" to access in the way the CFAA defines it. This is the most important web scraping legal precedent in the US, and it broadly protects scraping of public data. But that protection has four significant limits.
-
What's Generally Legal
- Scraping data publicly visible without logging in (prices, listings, public posts, open government data)
- Scraping for research, journalism, analysis, or competitive intelligence
- Scraping data you have a legitimate interest in collecting (your own product reviews, public mentions of your brand)
-
Where Legal Risk Exists
- Authenticated pages — scraping behind a login wall after accepting a ToS is a CFAA violation risk (the authorization analysis changes)
- ToS violations — even for public data, violating Terms of Service can lead to civil breach-of-contract claims (lower bar than CFAA)
- Personal data in the EU — collecting EU residents' personal data triggers GDPR obligations: legal basis, data minimization, retention limits
- Copyright — raw facts aren't copyrightable, but creative compilations can be; scraping a database's unique selection and arrangement may infringe
Best practice: Check
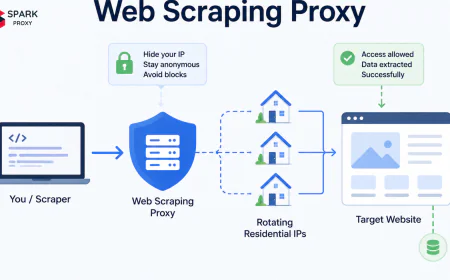
robots.txtbefore scraping (disrespecting it won't incur criminal liability, but courts have cited it in ToS claims). Rate-limit requests to avoid overloading servers (DDoS-adjacent behaviour creates liability regardless of data legality). Never scrape personal data without a GDPR-compliant legal basis.→ See also: What Is a Web Scraping Proxy? — Rotating IPs to scrape without IP bans
Ready to start scraping? Our Python web scraping tutorial covers setting up your environment, writing your first BeautifulSoup scraper, and adding proxy rotation to avoid blocks — with full working code for each step.
Read the Python Scraping Tutorial →
-
-
Conclusion
Web scraping is the foundational layer beneath competitive intelligence, financial data pipelines, academic datasets, and AI training corpora. The mechanics are straightforward — HTTP request, HTML parse, extract, store — but building reliable scrapers at scale requires matching your technique to the target (static vs. dynamic), keeping your selector logic maintainable as sites change, and routing through rotating proxies when anti-bot defenses activate.
The tooling has matured to the point where a functional scraper takes under 10 lines of Python. The real engineering challenge is keeping it running — handling rate limits, selector drift, and IP blocks — which is where proxy infrastructure and production frameworks like Scrapy earn their place.
→ Next: What Is a Web Scraping Proxy? How rotating IPs keep scrapers unblocked →