


What Is IP Blacklisting and How to Avoid It
IP blacklisting blocks specific IP addresses from accessing a server. Learn how blacklists work, what triggers them, and how to avoid getting banned.
-
What Is IP Blacklisting?
Key Takeaways
- IP blacklisting adds an address to a blocklist that causes servers to reject or throttle traffic from that IP.
- Blacklists operate at multiple layers: network-level (BGP/firewall), application-level (WAF/CDN), and reputation-database-level (third-party feeds like Spamhaus, Maxmind).
- The most common triggers are request rate anomalies, datacenter ASN registration, and behavioral signals that deviate from human browsing patterns.
- Residential and ISP proxy IPs avoid the most common detection layer — datacenter ASN registration — because they are registered to consumer ISPs.
- Rotating exit IPs, controlling request timing, and matching browser fingerprints are the primary strategies for avoiding blacklisting in automation workflows.
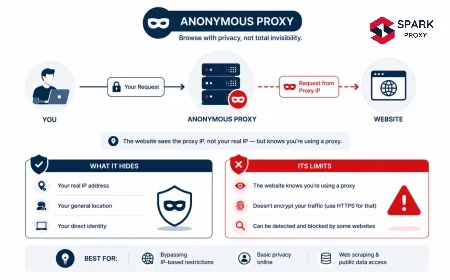
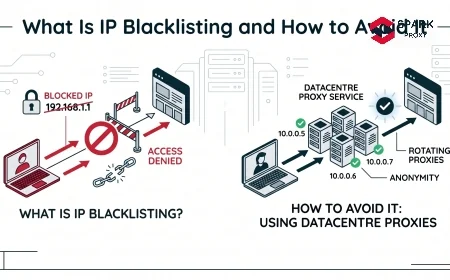
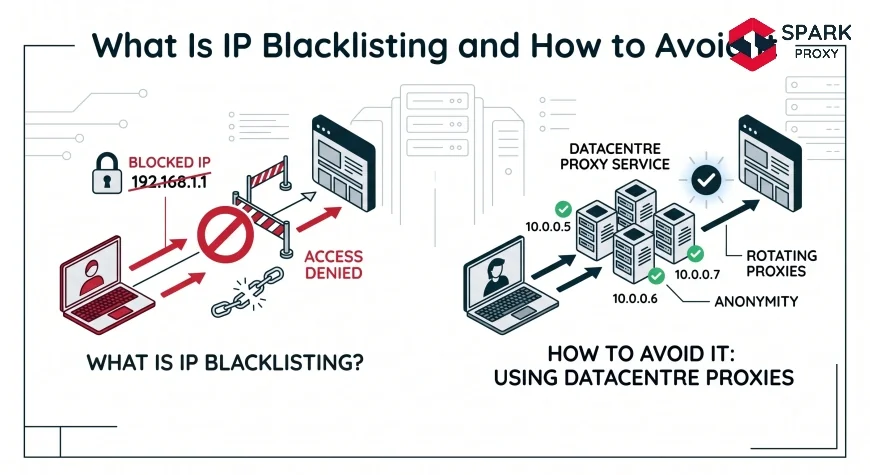
IP blacklisting is the practice of adding an IP address (or a range of addresses) to a deny list that causes servers, firewalls, or CDN edge nodes to reject, throttle, or challenge traffic originating from that address.
Blacklisting is not a single system — it is a category of enforcement that operates at multiple independent layers, each with different triggers, granularity, and remediation paths. An IP can be clean on one layer and blocked on another simultaneously. Understanding which layer blocked you determines how to respond.
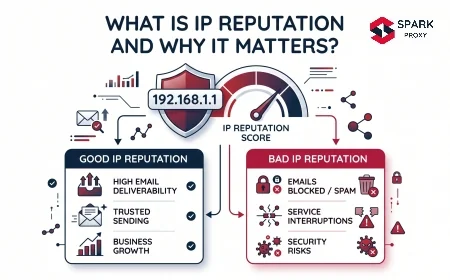
The inverse term — IP reputation scoring — is more commonly used in modern systems. Instead of a binary allow/deny list, reputation systems assign a continuous risk score to each IP based on aggregated behavioral signals from multiple sources. A score above a threshold triggers blocking or CAPTCHA; a score in an intermediate range triggers additional friction like JavaScript challenges. Pure binary blocklists still exist (particularly for spam and abuse), but most web application firewalls and CDNs use reputation scoring under the hood.
-
What Are the Main Types of IP Blacklists?
| Blacklist Type | Operated By | Scope | Common Trigger |
|---|---|---|---|
| Email/spam blacklists | Spamhaus, SORBS, Barracuda | Mail servers | Sending spam, open relays |
| Threat intelligence feeds | Crowdstrike, Emerging Threats, CINS Army | Firewalls, IDS/IPS | Port scanning, exploit attempts |
| CDN/WAF reputation | Cloudflare, Akamai, Fastly (internal) | HTTP layer | Rate violations, scraping patterns |
| Application-layer blocklists | Site operators (custom rules) | Single domain | Behavior patterns, user-agent strings |
| ASN/datacenter blocklists | Site operators + CDNs | Datacenter IP ranges | IP registered to hosting/cloud ASN |
| Residential proxy detection | IPQualityScore, Scamalytics, IPDB | Multiple sites | Exit node flagged by behavior history |
For automation and scraping workflows, the most operationally relevant layers are CDN/WAF reputation (Cloudflare, Akamai, Fastly), application-layer blocklists maintained by the target site, and ASN-level datacenter blocking. Email spam blacklists are irrelevant for HTTP traffic unless the site checks IP reputation via an external API that aggregates spam signals.
-
What Triggers IP Blacklisting?
Request rate anomalies are the most common trigger. A human browsing a website makes requests at irregular intervals — reading time between page loads, mouse movements, form interactions. An automated script making 10 requests per second with identical inter-request intervals matches no known human behavior pattern. Rate limiting fires before a site-level blacklist is applied; persistent rate violations escalate to a blocklist entry.
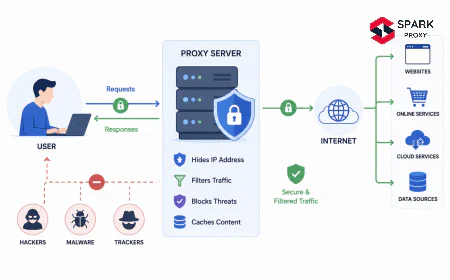
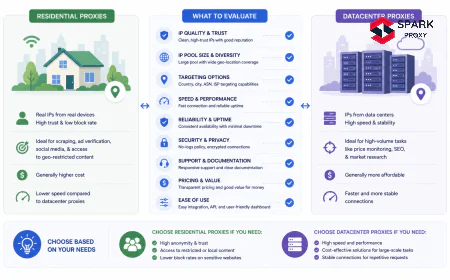
Datacenter ASN registration is a structural trigger that fires regardless of request behavior. Most major sites query the ASN of the incoming IP on every request. If the ASN is registered to Amazon Web Services, Google Cloud, DigitalOcean, or any recognizable hosting provider, the request is flagged automatically — even at a rate of one request per hour. Datacenter IPs are treated as non-human by default. Residential and ISP proxies bypass this layer because their IPs are registered to consumer ISPs (Comcast, BT, Deutsche Telekom, etc.), which are the same ASNs real users originate from. See What Is a Residential Proxy? for the technical basis of this distinction.
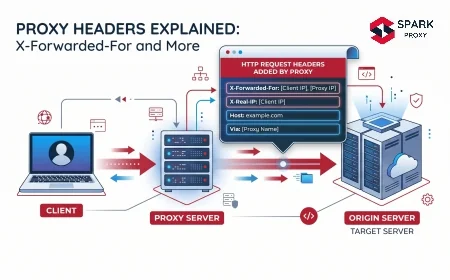
User-agent and header anomalies are another common trigger. A request arriving with
User-Agent: python-requests/2.31.0orUser-Agent: curl/8.1.2is immediately identifiable as automated. Missing standard browser headers (Accept-Language,Accept-Encoding,Sec-Fetch-*family) are equally distinctive. Modern WAFs maintain fingerprint databases of common HTTP client libraries and flag them without any rate-based signal. For a detailed treatment of header-level detection, see Proxy Anonymity Levels Explained.TLS fingerprint mismatches reveal automated clients even when HTTP headers are spoofed. The JA3 fingerprint is computed from the TLS
ClientHelloparameters — cipher suites, extensions, elliptic curves, and their ordering. Python'srequestslibrary (using OpenSSL) produces a JA3 fingerprint that is well-known and cataloged. The fingerprint does not change when you set a fakeUser-Agentheader; it is a property of the TLS stack, not the application layer. Matching the TLS fingerprint of a real browser requires using a browser-based automation tool (Playwright, Puppeteer) or a library with TLS fingerprint spoofing capabilities (curl-impersonate, tls-client).Behavioral pattern analysis is applied by advanced bot detection platforms (Cloudflare Bot Management, Akamai Bot Manager, DataDome, Imperva). These systems analyze request sequences, timing distributions, mouse movement patterns (for JavaScript-enabled sessions), and session-level behavioral entropy. An IP that makes requests with statistically uniform inter-request timing, skips all static asset loads, and never triggers hover or scroll events accumulates a high bot probability score regardless of the IP type or headers presented.
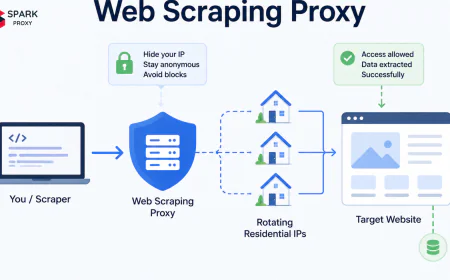
IP reputation inheritance from prior use occurs when an IP was previously used by another client that triggered blacklisting. Shared proxy pools accumulate reputation damage over time as multiple clients use the same IPs for varying purposes. This is why freshness and exclusivity of the IP pool matters. Reputable proxy providers rotate IPs regularly and remove flagged addresses from active rotation.
-
How Do Sites Detect Proxy and VPN IPs?
Sites use several independent signals to identify proxy and VPN usage, which then triggers heightened scrutiny or blocking:
ASN lookup: Every IP block is registered to an Autonomous System Number (ASN) via ARIN, RIPE NCC, APNIC, LACNIC, or AFRINIC. The ASN's organization name reveals whether the IP block belongs to a residential ISP, a cloud provider, a hosting company, or a known proxy provider. This lookup is a synchronous database query on every request — it adds negligible latency and has near-perfect accuracy for datacenter IPs.
IP reputation database APIs: Services like IPQualityScore, Scamalytics, ip-api.com (Pro tier), and Maxmind GeoIP2 Insights include proxy/VPN/Tor detection flags. These databases aggregate behavioral signals, abuse reports, and network measurements to assign a proxy probability score to each IP. Sites query these APIs in real time or maintain cached versions of the risk scores.
Port scanning and banner grabbing: Some detection systems probe the source IP for open proxy ports (3128, 8080, 1080) or HTTP proxy response headers. This is less common for casual scraping detection but is used in fraud prevention contexts.
DNS reverse lookup: Legitimate residential IPs typically have PTR records matching the ISP's naming convention (
pool-72-82-100-200.hrtc.net). Datacenter IPs often have PTR records naming the hosting provider (ec2-54-239-100-1.compute-1.amazonaws.com). Missing PTR records or records naming known proxy providers are a weak but additive signal.JavaScript fingerprinting: Browser-based sites can use JavaScript to probe the client environment: canvas fingerprint, WebGL renderer, audio context fingerprint, installed fonts, screen resolution, timezone, and navigator properties. Headless browsers (Playwright, Puppeteer without stealth plugins) expose distinctive fingerprints that bot detection platforms maintain signatures for.
navigator.webdriver = truein a headless Chrome instance is the most obvious signal, but stealth patches address this. -
How Do You Avoid IP Blacklisting?
Use residential or ISP proxy IPs. This is the highest-leverage single change for most scraping and automation workflows. Residential IPs bypass ASN-based blocking entirely because they register to consumer ISPs. The IP type is the first filter most sites apply, and datacenter IPs fail it by definition. See What Is a Residential Proxy? for pool selection criteria and use-case fit.
Control request rate and timing. Distribute requests over time with randomized inter-request delays drawn from a distribution that approximates human reading time. A uniform 1-second delay is as detectable as no delay — the uniformity itself is a bot signal. Use a log-normal distribution for delays: most waits are short (1–3 seconds), a few are longer (10–30 seconds), with occasional page-read pauses. Match the request rate to what a human would plausibly do on the target site.
```python
import time
import random
import math
def human_delay(mean_seconds: float = 2.5, sigma: float = 0.8) -> None:
"""
Sleep for a duration drawn from a log-normal distribution.
Approximates human inter-request timing with short-tailed randomness.
mean_seconds: geometric mean of the delay in seconds
sigma: log-normal shape parameter (higher = more variance)
"""
delay = random.lognormvariate(math.log(mean_seconds), sigma)
delay = max(0.5, min(delay, 30.0)) # Clamp to [0.5s, 30s]
time.sleep(delay)
```
Rotate IPs across requests. A rotating proxy assigns a different exit IP to each request (or to each configurable batch of requests), distributing your request fingerprint across many IPs. No single IP accumulates enough request volume to trigger rate-based detection. For configuration of rotating vs sticky modes, see What Is a Sticky Session Proxy?.
Match browser HTTP headers. Set
User-Agentto a current, common browser string, and include the full set of headers a real browser would send. At minimum:Accept,Accept-Language,Accept-Encoding,Connection, and theSec-Fetch-*family introduced in Chrome 80. The order of headers in the HTTP request also matters — browsers send headers in a specific order that differs from the defaults of HTTP libraries.```python
import requests
BROWSER_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
}
proxies = {
"http": "http://user-session-abc123:[email protected]:10000",
"https": "http://user-session-abc123:[email protected]:10000",
}
response = requests.get("https://example.com", headers=BROWSER_HEADERS, proxies=proxies)
```
Address TLS fingerprinting. If the target uses JA3-based detection,
requestswith its default OpenSSL cipher suite ordering will be flagged. Options: use Playwright/Puppeteer for a real browser TLS stack; usecurl-impersonate(which patches libcurl to match Chrome/Firefox TLS parameters); or usetls-clientPython library which provides pre-configured browser profiles. For most scraping, Playwright with a persistent browser profile is the highest-fidelity approach.Respect crawl delays and robots.txt. Sites publish
Crawl-delaydirectives inrobots.txtfor automated clients. Honoring these signals marks your client as a well-behaved crawler, reducing the likelihood of triggering WAF rules. Legitimate search engine bots honorrobots.txt; bot detection systems give lower bot scores to clients that do as well. Note thatrobots.txtis advisory — it is not access control, and honoring it does not grant legal permission to scrape.Monitor your IP reputation proactively. Check assigned proxy IPs against reputation APIs before committing to a workflow run. IPQualityScore, Scamalytics, and
ip-api.com(Pro) all offer single-IP lookups. A quick pre-flight check identifying high-risk IPs avoids wasting session budget on IPs that will be blocked on arrival.```python
import requests
def check_ip_reputation(ip: str, api_key: str) -> dict:
"""
Query IPQualityScore for proxy/VPN/bot flags on the given IP.
Returns the JSON response with fraud_score, proxy, vpn, bot_status fields.
"""
url = f"https://www.ipqualityscore.com/api/json/ip/{api_key}/{ip}"
r = requests.get(url, timeout=10)
r.raise_for_status()
data = r.json()
return {
"ip": ip,
"fraud_score": data.get("fraud_score"),
"proxy": data.get("proxy"),
"vpn": data.get("vpn"),
"bot_status": data.get("bot_status"),
"is_crawler": data.get("is_crawler"),
}
```
-
What Should You Do When You Are Already Blacklisted?
Identify the blacklist layer first. The response code and response body tell you which layer is rejecting you:
| Response | Likely Layer | Action |
|---|---|---|
|
403 Forbidden+ Cloudflare HTML | CDN WAF | New IP, fix fingerprint ||
429 Too Many Requests+Retry-Afterheader | Application rate limiter | Slow down, respect header ||
403 Forbidden+ blank or minimal body | Application-level blocklist | New IP from different ASN ||
Connection refused/ timeout | Firewall/network-level | IP-level block; new IP range needed ||
200 OK+ CAPTCHA challenge page | Bot scoring friction | Browser automation, fingerprint improvement ||
200 OK+ empty/incorrect content | Honeypot/soft-block | IP flagged; silently serving decoy content |Rotate to a new IP immediately. If you are using a rotating proxy, the next request automatically uses a fresh IP. If you are using sticky sessions, start a new session with a new token to get a different exit IP. For bandwidth and session management during recovery, see Understanding Proxy Uptime and Reliability.
Do not retry aggressively on a blocked IP. Repeated requests from a blacklisted IP escalate the block duration, add the IP to longer-retention blocklists, and may trigger security alerts that cause the site to block your entire IP range. Detect the block response, log it, abandon the IP, and continue from a clean one.
Implement exponential backoff with jitter for rate limit responses (
429). A fixed retry interval — even with a delay — sends requests at predictable intervals that compound the rate signal. Jitter randomizes the retry timing:```python
import time
import random
def backoff_retry(attempt: int, base_delay: float = 1.0, max_delay: float = 60.0) -> float:
"""Return jittered exponential backoff delay for the given attempt number."""
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.3)
return delay + jitter
for attempt in range(5):
response = requests.get(url, headers=BROWSER_HEADERS, proxies=proxies)
if response.status_code == 429:
wait = backoff_retry(attempt)
time.sleep(wait)
continue
break
```
-
How Do You Check If Your IP Is on a Public Blacklist?
For email/network-level blacklists, MXToolbox and MultiRBL aggregate checks across 100+ public blacklist databases. These are most useful for diagnosing mail delivery issues or network-level blocks affecting server infrastructure.
For HTTP/automation use cases, query the reputation APIs directly:
```python
import requests
def bulk_reputation_check(proxy_url: str, test_ips: list[str], api_key: str) -> list[dict]:
"""
Check a list of proxy exit IPs against IPQualityScore.
Returns only IPs with fraud_score > 50 or proxy/vpn flags set.
"""
results = []
for ip in test_ips:
rep = check_ip_reputation(ip, api_key)
if rep["fraud_score"] > 50 or rep["proxy"] or rep["vpn"]:
results.append(rep)
return results
```
Most proxy providers publish their own IP health dashboards or allow you to filter the IP pool by freshness and reputation score. When evaluating a provider, ask specifically: how often are IPs rotated out of the active pool, what is the mean time between a blacklist event and removal from rotation, and does the platform allow you to exclude high-risk-score IPs from your allocation? For uptime and availability implications of IP pool health, see Understanding Proxy Uptime and Reliability.
Frequently Asked Questions {#faq}
It depends on the blacklist type and severity. Application-level soft blocks for rate violations typically expire in minutes to hours. CDN/WAF reputation entries may persist for days if the IP is not further flagged. Third-party reputation database entries (IPQualityScore, Scamalytics) can persist for weeks or months after the triggering behavior stops, and require a formal removal request through each provider's delisting process. Network-level firewall ACL entries set by site operators can be permanent unless the operator actively audits and expires them. For proxy IPs specifically, reputation damage is concentrated on the specific exit IP — rotating to a new IP from the same provider's pool immediately gives you a clean reputation.
No. IP blacklisting operates at the network layer — it fires on the source IP address before the protocol or payload is examined. A 403 Forbidden from a WAF is returned after the TCP connection is established and the HTTP request is parsed, but the ban decision was based on the IP reputation score computed before the request was read. HTTPS encrypts the payload between your client and the destination, but the source IP address is visible in every TCP packet header and cannot be encrypted.
Yes. Subnet-level blocking is common for datacenter IP ranges. If one IP in a /24 block (256 addresses) at a cloud provider is used for abuse, the site may block the entire /24 or even the cloud provider's entire ASN allocation. This is why datacenter proxies carry inherent structural risk regardless of your individual behavior — you share an address space with other tenants whose behavior affects your IP's reputation. Residential IPs are individually registered to consumer devices in geographically distributed locations; shared-subnet reputation damage is not a meaningful risk for residential pools.
No. A CAPTCHA challenge is a friction mechanism that asks you to prove human identity before proceeding. It is typically triggered at an intermediate bot score — high enough to flag as suspicious, low enough to warrant verification rather than outright blocking. A blacklist entry triggers an outright 403 Forbidden or connection drop without offering a challenge. Many sites use a layered approach: low-risk IPs pass freely, medium-risk IPs receive CAPTCHA challenges, high-risk or blacklisted IPs receive hard blocks.
IP rotation prevents per-IP request accumulation, which eliminates rate-based blacklisting on individual IPs. It does not prevent session-level behavioral detection (if the same browser fingerprint, cookie, or account appears across many IPs, the session itself may be flagged), and it does not prevent ASN-based blocking if you rotate within a datacenter IP pool. Effective anti-blacklisting combines IP rotation with behavioral mimicry, browser-quality fingerprints, and residential IP types — rotation alone addresses one detection layer out of several.