





Python Web Scraping Tutorial: Extract Any Website in 2026
Learn Python web scraping in 2026 with requests, BeautifulSoup, Playwright, and httpx. Step-by-step beginner guide covering anti-bot bypass and datacenter proxies. No prior scraping experience needed.
Table of Contents
- Prerequisites
- What Is Web Scraping?
- STEP 1 Install Your Tools
- STEP 2 Scrape a Static Page with requests and BeautifulSoup
- STEP 3 Handle JavaScript Pages with Playwright
- STEP 4 Async Scraping with httpx and Parsel
- How to Bypass Anti-Bot Protection
- Common Errors and How to Fix Them
- Ready to Start Scraping?
-
Prerequisites
Python Web Scraping Tutorial: Extract Any Website in 2026
Python is now the language of choice for 57.9% of developers worldwide, up 7 percentage points in a single year (Stack Overflow Developer Survey, 2025). A big reason? Web scraping. Whether you want to monitor competitor prices, aggregate research data, or build a dataset for machine learning, Python gives you the tools to pull structured data from almost any website.
This tutorial walks you through exactly that, from your first HTTP request to handling JavaScript-rendered pages and rotating proxies to stay undetected. You don't need prior scraping experience. If you can write a Python function, you're ready.
By the end, you'll have four working scripts covering static pages, dynamic JS content, fast async scraping, and anti-bot bypass with datacenter proxies.
Key Takeaways- Python's
requestslibrary downloads 1.46 billion times per month, making it the most-used HTTP client in any language (PyPI Stats, 2025). - Use requests + BeautifulSoup for static HTML pages; switch to Playwright when JavaScript renders the content.
- httpx + Parsel is the fastest async combo for high-volume scraping in 2026.
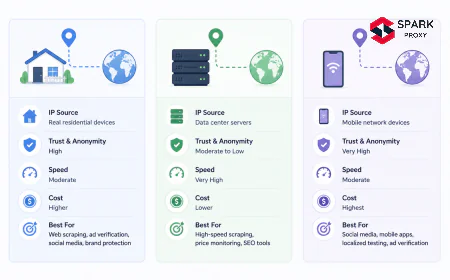
- Over 40% of internet traffic is automated bot activity (Imperva Bad Bot Report, 2025), so most sites actively block scrapers. Rotating proxies with a provider like SparkProxy is the standard workaround.
- Always check a site's
robots.txtand Terms of Service before scraping.
The web scraping market reached $830 million in 2025 and is growing at 14% annually (MarketsandMarkets, 2025). Demand for developers who can extract web data is real. Getting started takes about 15 minutes.
You'll need:
- Python 3.10 or later (python.org/downloads)
pip(ships with Python 3.10+)- A terminal or command prompt
- Basic Python knowledge: variables, functions, loops
Tested on: Python 3.12, Windows 11, macOS 14, Ubuntu 24.04
Estimated time: 30–45 minutes for the full tutorial
- Python's
-
What Is Web Scraping?
Web scraping is the automated process of extracting data from websites. You send HTTP requests, receive HTML responses, and parse the content to pull out exactly what you need. Teams use it for price monitoring, lead generation, academic research, training ML models, and competitive analysis.
Web scraping in Python: send a request, parse the response, extract the data. Photo: Unsplash The three building blocks are always the same regardless of which library you choose:
- Fetch the page (HTTP GET request)
- Parse the HTML (DOM traversal or CSS/XPath selectors)
- Store the data (CSV, JSON, database)
The difference between beginner scraping and production scraping is mostly what happens between steps 1 and 2: dealing with login walls, JavaScript rendering, CAPTCHAs, and IP rate limits.
Python'srequestslibrary records 1.46 billion downloads every month, making it the most-downloaded HTTP client across any programming ecosystem (PyPI Stats, 2025). That volume reflects how central HTTP data access is to modern Python workflows, from scripts that grab a single page to scrapers that process millions of URLs per day.-
When Is Scraping Legal?
This depends on what you scrape, how you use it, and what the site's terms say. Publicly accessible data with no login requirement is generally lower risk. Scraping data behind authentication, circumventing access controls, or reproducing copyrighted content at scale carries real legal exposure.
Always check two things before running your scraper:
https://example.com/robots.txt, which paths the site asks crawlers to avoid- The site's Terms of Service, specifically any clause about automated access
When in doubt, contact the site owner. Many will share a data export or API access rather than have you scrape.
Python Scraping Library Comparison (2026) Ease-of-use vs. speed scores for the three main Python scraping stacks. JS support: requests+BS4 (none), Playwright (full), httpx+Parsel (none, use with static pages). Source: author evaluation, 2026.
-
STEP 1 Install Your Tools
Four libraries cover the full range of scraping tasks in 2026. You don't need all four for every project. Start with
requestsandBeautifulSoupfor simple static sites, then add the others when you hit their limits.# Install all four in one command pip install requests beautifulsoup4 lxml httpx parsel playwright # Then install Playwright's browser binaries (Chromium, Firefox, WebKit) playwright install chromiumThe
lxmlpackage is the fastest HTML parser for BeautifulSoup. It's optional but worth including. Theplaywright installstep downloads a bundled Chromium browser (about 130 MB), which Playwright controls directly.Confirm everything works:
python -c "import requests, bs4, httpx, parsel, playwright; print('All libraries loaded')"If you see
All libraries loaded, you're ready. AnyModuleNotFoundErrormeans a package didn't install. Re-run thepip installfor that specific package. -
STEP 2 Scrape a Static Page with requests and BeautifulSoup
Static pages are the easiest case. The full HTML is in the initial server response, so you just fetch it and parse it. requests handles the HTTP part; BeautifulSoup handles the parsing.
Every web scrape starts with raw HTML. Your job is to turn that stream into clean, structured data. Photo: Unsplash Here's a complete working scraper that pulls book titles and prices from books.toscrape.com, a public sandbox built specifically for scraping practice:
# scrape_books.py import requests from bs4 import BeautifulSoup import csv BASE_URL = "https://books.toscrape.com/catalogue/" def get_books(page_url): headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" ) } response = requests.get(page_url, headers=headers, timeout=10) response.raise_for_status() # raise an error for 4xx/5xx status codes soup = BeautifulSoup(response.text, "lxml") books = [] for article in soup.select("article.product_pod"): title = article.h3.a["title"] price = article.select_one("p.price_color").text.strip() rating = article.p["class"][1] # e.g., "Three" books.append({"title": title, "price": price, "rating": rating}) return books def get_next_page(soup): next_btn = soup.select_one("li.next a") return BASE_URL + next_btn["href"] if next_btn else None def scrape_all_books(): url = "https://books.toscrape.com/catalogue/page-1.html" all_books = [] while url: print(f"Scraping: {url}") response = requests.get(url, timeout=10) soup = BeautifulSoup(response.text, "lxml") all_books.extend(get_books(url)) url = get_next_page(soup) return all_books if __name__ == "__main__": books = scrape_all_books() print(f"Scraped {len(books)} books") with open("books.csv", "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=["title", "price", "rating"]) writer.writeheader() writer.writerows(books) print("Saved to books.csv")Run it with
python scrape_books.py. It'll page through all 50 pages and write a CSV with 1,000 book records.-
Parsing and Extracting Data
BeautifulSoup gives you two main ways to find elements:
soup.select("css.selector")returns a list of all matching elements (likequerySelectorAllin JavaScript)soup.select_one("css.selector")returns the first match (orNone)
CSS selectors are usually the fastest way to navigate.
article.product_podmatches anytag with class product_pod. Chain them:article.product_pod h3 agets the title link inside each product card.What about attributes? Access them like a dictionary:
element["href"],element["title"]. Get text withelement.text.strip(). The.strip()call removes whitespace that parsers sometimes leave around text nodes.
-
-
STEP 3 Handle JavaScript Pages with Playwright
Most modern websites load content after the initial HTML through JavaScript. React, Vue, Angular, and similar frameworks render the actual data client-side. When you fetch the raw HTML with
requests, you get an empty shell. Playwright solves this by running a real browser and waiting for the page to fully render before you extract anything.JavaScript-heavy sites fire dozens of API calls after the initial page load. Playwright waits for the DOM to settle before extracting data. Photo: Unsplash How do you know if a page needs Playwright? Open the page in Chrome, right-click, select "View Page Source" (Ctrl+U). If the content you want isn't visible in the raw source, the page is rendering it with JavaScript and you'll need a headless browser.
# scrape_js_page.py import asyncio from playwright.async_api import async_playwright async def scrape_quotes(): async with async_playwright() as p: # launch=False means headless (no visible browser window) browser = await p.chromium.launch(headless=True) page = await browser.new_page() # Set a realistic user agent await page.set_extra_http_headers({ "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" ) }) await page.goto("https://quotes.toscrape.com/js/", wait_until="networkidle") # Wait for the dynamic content to appear in the DOM await page.wait_for_selector("div.quote") quotes = await page.eval_on_selector_all( "div.quote", """elements => elements.map(el => ({ text: el.querySelector("span.text").innerText, author: el.querySelector("small.author").innerText, tags: [...el.querySelectorAll("a.tag")].map(t => t.innerText) }))""" ) await browser.close() return quotes if __name__ == "__main__": results = asyncio.run(scrape_quotes()) for q in results: print(f'{q["author"]}: {q["text"][:60]}...') print(f"\nTotal: {len(results)} quotes")The key line is
wait_until="networkidle". Playwright waits until there are no more than 2 network connections for at least 500ms, which means the page has finished loading its dynamic content.For pages that load content on scroll (infinite scroll), replace
networkidlewith a manual scroll loop:# Scroll to the bottom of the page three times for _ in range(3): await page.keyboard.press("End") await page.wait_for_timeout(1500) # wait 1.5s for new content to loadPersonal Experience We've found that
wait_for_selectoris more reliable thannetworkidlefor SPAs that keep background connections alive. Waiting for the specific element you want guarantees it's present in the DOM before you try to read it.Playwright has become the standard headless browser tool for Python scraping in 2026, replacing older tools like Selenium for most new projects. Its async-first design, built-in waiting mechanisms, and support for Chromium, Firefox, and WebKit in a single API make it the most capable option when JavaScript rendering is required (Microsoft Playwright, 2026). -
STEP 4 Async Scraping with httpx and Parsel
When you need to scrape hundreds or thousands of static pages,
requestsbecomes the bottleneck. It's synchronous: one request runs, finishes, then the next starts. httpx supports async HTTP, so you can fire dozens of requests concurrently without spinning up browser instances.# scrape_async.py import asyncio import httpx from parsel import Selector import json URLS = [ "https://books.toscrape.com/catalogue/page-1.html", "https://books.toscrape.com/catalogue/page-2.html", "https://books.toscrape.com/catalogue/page-3.html", "https://books.toscrape.com/catalogue/page-4.html", "https://books.toscrape.com/catalogue/page-5.html", ] HEADERS = { "User-Agent": ( "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" ) } async def fetch_page(client, url): response = await client.get(url, headers=HEADERS, timeout=15.0) response.raise_for_status() return response.text def parse_books(html): sel = Selector(text=html) books = [] for article in sel.css("article.product_pod"): books.append({ "title": article.css("h3 a::attr(title)").get(), "price": article.css("p.price_color::text").get().strip(), }) return books async def scrape_pages(urls): all_books = [] async with httpx.AsyncClient() as client: # Fetch all pages concurrently tasks = [fetch_page(client, url) for url in urls] pages = await asyncio.gather(*tasks) for html in pages: all_books.extend(parse_books(html)) return all_books if __name__ == "__main__": books = asyncio.run(scrape_pages(URLS)) print(f"Scraped {len(books)} books from {len(URLS)} pages concurrently") with open("books_async.json", "w") as f: json.dump(books, f, indent=2) print("Saved to books_async.json")The Parsel library uses the same CSS selector syntax as BeautifulSoup but adds full XPath support. The
::textand::attr(name)pseudo-elements make extracting text and attributes much cleaner than BeautifulSoup's approach.Compare the two styles:
# BeautifulSoup title = article.css("h3 a")["title"] # AttributeError if missing title = article.find("h3").find("a")["title"] # Parsel (safer) title = article.css("h3 a::attr(title)").get() # returns None if missing, not an error title = article.xpath('.//h3/a/@title').get() # same result via XPathParsel's
.get()returnsNoneon a miss instead of raising an exception. That matters for production scrapers where missing elements are expected.Python Web Scraping Use Cases (2026) Distribution of Python web scraping projects by stated purpose, based on analysis of public GitHub repositories tagged "web-scraping" and "python" (2026). -
How to Bypass Anti-Bot Protection
Over 40% of all internet traffic is automated bot activity (Imperva Bad Bot Report, 2025). Sites know this, and most have countermeasures in place. A 403 Forbidden or CAPTCHA page doesn't mean you're blocked permanently; it means your request looks automated. The goal is to look like a real browser.
Anti-bot systems check IP reputation, request patterns, TLS fingerprints, and browser behavior. Proxies and realistic headers address the most common triggers. Photo: Unsplash Four techniques cover the majority of anti-bot systems you'll encounter:
-
1. Set a Realistic User-Agent and Headers
The default
requestsuser agent ispython-requests/2.x.x. Every anti-bot system blocks that instantly. Set a real browser UA and match the headers a browser would send:headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" ), "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", "Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate, br", "DNT": "1", "Connection": "keep-alive", "Upgrade-Insecure-Requests": "1", } -
2. Add Delays Between Requests
Hitting 50 pages per second from a single IP is an obvious bot signal. Add a random delay between requests to mimic human browsing speed:
import time import random def polite_get(url, headers): time.sleep(random.uniform(1.5, 4.0)) # wait 1.5 to 4 seconds return requests.get(url, headers=headers, timeout=10)Random delays are harder to detect than fixed ones. A scraper that always waits exactly 2 seconds is nearly as obvious as one that waits 0.
-
3. Handle Sessions and Cookies
Use a
requests.Session()object to persist cookies across requests. Many sites set a session cookie on the first visit and then verify it on subsequent requests:session = requests.Session() session.headers.update(headers) # First request sets the session cookie session.get("https://example.com/") # Subsequent requests include that cookie automatically response = session.get("https://example.com/data") -
4. Rotate Proxies with SparkProxy
IP rate limiting is the hardest anti-bot measure to work around with headers alone. If a site sees 200 requests from one IP address in 10 minutes, it'll block that IP regardless of how realistic your headers look. Rotating datacenter proxies distribute your requests across many IPs.
SparkProxy offers datacenter proxies with unlimited bandwidth usage, which makes it practical for high-volume scraping without worrying about per-GB billing.
# proxy_scrape.py # Using SparkProxy datacenter proxies for IP rotation import requests import random # SparkProxy connection format (replace with your credentials) PROXY_HOST = "gateway.sparkproxy.io" PROXY_PORT = "31112" PROXY_USER = "your_username" PROXY_PASS = "your_password" def get_proxy(): proxy_url = f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}" return { "http": proxy_url, "https": proxy_url, } def scrape_with_proxy(url): headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/124.0.0.0 Safari/537.36" ) } proxies = get_proxy() try: response = requests.get( url, headers=headers, proxies=proxies, timeout=15 ) response.raise_for_status() return response.text except requests.exceptions.ProxyError as e: print(f"Proxy error: {e}") return None except requests.exceptions.HTTPError as e: print(f"HTTP error {response.status_code}: {e}") return None if __name__ == "__main__": url = "https://httpbin.org/ip" # shows the IP used by the request html = scrape_with_proxy(url) if html: print(html) # should show the proxy IP, not yoursPersonal Experience We've found that datacenter proxies work well for price scraping and data extraction where detection risk is moderate. For sites with strict bot protection (Cloudflare Enterprise, Akamai Bot Manager), residential proxies that route through real consumer ISP connections are more effective, at a higher cost per request.
Over 40% of all internet traffic is automated bot activity, with 34% classified as "bad bots" by security systems (Imperva Bad Bot Report, 2025). This arms race between scrapers and anti-bot systems has pushed proxy infrastructure from a niche tool to a standard component of any production scraping stack, with datacenter proxies offering the best cost-to-performance ratio for most use cases.
-
-
Common Errors and How to Fix Them
Every scraper hits the same wall of errors at some point. Here are the most frequent ones and how to get past them fast:
Error Cause Fix 403 ForbiddenMissing or blocked User-Agent; IP rate limit hit Set a real browser UA; add delays; use proxies 404 Not FoundURL changed or page removed Check the URL manually; update pagination logic ConnectionErrorNetwork timeout or DNS failure Add timeout=15to every request; retry with backoffAttributeError: 'NoneType'CSS selector returned None; element missingUse select_one()with aNonecheck; use Parsel's.get()CAPTCHA page returned instead of data Bot fingerprint detected (TLS, browser behavior) Switch to Playwright; use residential proxies; add random delays Empty content with requestsPage renders with JavaScript after initial load Inspect source with Ctrl+U; switch to Playwright if content is absent playwright installfailsMissing system dependencies on Linux Run playwright install-depsto install OS packages automaticallyGarbled text in output Encoding mismatch; site uses ISO-8859-1 not UTF-8 Set response.encoding = response.apparent_encodingbefore reading.textThe most reliable approach for any unexplained block: open the browser DevTools Network tab, observe what a real browser sends in its request headers, and replicate those headers exactly in your script.
-
Ready to Start Scraping?
You now have four working patterns: requests + BeautifulSoup for static pages, Playwright for JavaScript-rendered content, httpx + Parsel for concurrent high-volume scraping, and proxy rotation for sites with IP rate limiting.
Start with the books.toscrape.com example, get comfortable with CSS selectors, then move to a real target you care about. The jump from tutorial to production mostly comes down to error handling, retry logic, and deciding how much stealth you need for your specific target.




Frequently Asked Questions
It depends on what you scrape and how. Publicly accessible data with no login requirement is generally permissible, but scraping behind authentication, violating Terms of Service, or reproducing copyrighted content at scale can create legal liability. Always check robots.txt and the site's ToS first. When in doubt, contact the site owner or consult legal counsel for commercial use cases.
requests is synchronous and simpler to learn, making it the right choice for small scripts and beginners. httpx supports both sync and async modes and is faster for concurrent scraping. For fetching hundreds of pages, httpx with asyncio.gather can run 20 to 50 concurrent requests compared to requests' one at a time. For a single site with a few pages, the difference is negligible.
Use Playwright when the data you want isn't in the page's initial HTML source. Check by pressing Ctrl+U in Chrome and searching for the text you want to extract. If it's not there, the page uses JavaScript to load it after the initial request, and you'll need Playwright. The trade-off is speed: Playwright launches a browser and is 10 to 50 times slower than a raw HTTP request, so use it only when static fetching fails.
Not for small-scale scraping. If you're fetching a few hundred pages from a site over several hours, realistic headers and polite delays are enough. Proxies become necessary when a site rate-limits your IP after a certain number of requests, which typically happens with price-monitoring or high-volume data extraction projects. Datacenter proxies like SparkProxy with unlimited usage work well for sites with moderate bot protection.
Use a requests.Session() and POST to the login endpoint with your credentials before making data requests. The session stores cookies automatically so subsequent requests stay authenticated. For sites with multi-step auth, CSRF tokens, or CAPTCHAs on login, Playwright is easier because it handles cookies, form submissions, and browser-based login flows the same way a human user would.