


Manage Per-IP Rate Limits with Rotating Proxies (2026)
Scrapers hit per-IP limits within minutes on protected sites. Learn rotation strategies, backoff patterns, and a Python proxy manager that keeps success rates above 90%.
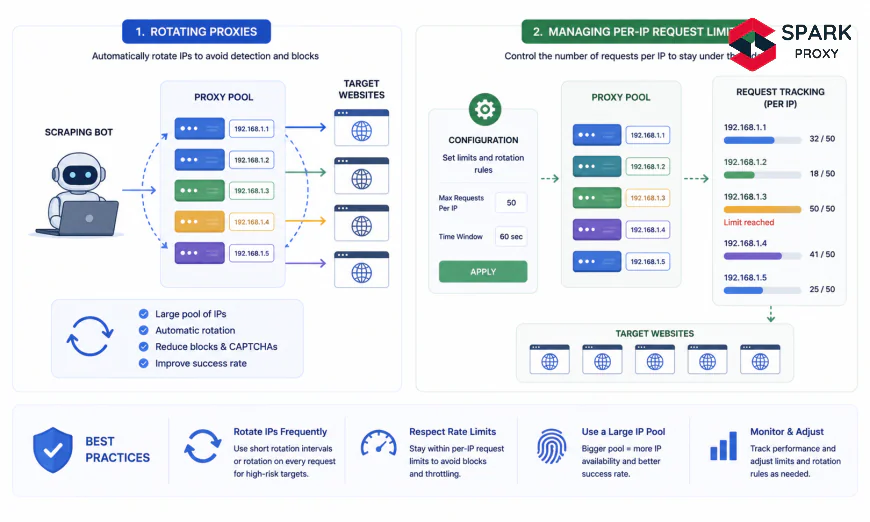
Table of Contents
- What Are Rotating Proxies and Why Do Per-IP Limits Break Scrapers?
- What Do You Need Before You Start?
- Which Rotation Strategy Should You Use?
- How Do You Configure a Backconnect Proxy in Python?
- How Do You Set Per-IP Request Budgets?
- How Do You Handle 429 and 503 Rate Limit Responses?
- Why Should You Classify Scraping Targets by Protection Tier?
- How Do You Track IP Health and Retire Burned Addresses?
- Putting It Together: A Complete Rotating Proxy Manager
- Conclusion
-
What Are Rotating Proxies and Why Do Per-IP Limits Break Scrapers?
Most scrapers don't fail because of bad code. They fail because they ignore the one variable that determines whether requests succeed or get blocked: how many times the same IP address hits the same server in a given window. Imperva's 2025 Bad Bot Report found that nearly 50% of all internet traffic is now non-human, and anti-bot systems have calibrated their per-IP thresholds precisely to filter that load.
Cross a target's per-IP budget, and you get throttled, CAPTCHAed, or hard-banned. The IP is now useless for that domain. If your scraper doesn't rotate, it hits that ceiling and stops. If it rotates badly — without tracking per-IP usage or implementing backoff on failure responses — it burns through a pool of addresses faster than any budget can sustain.
This guide walks through every layer of the solution: picking a rotation mode, configuring a backconnect proxy in Python, setting per-IP request budgets before the server enforces them, implementing exponential backoff on 429s, classifying targets by protection tier, and monitoring IP health in a persistent pool. All code is Python 3.11+.
Key Takeaways
- Nearly 50% of web traffic is non-human (Imperva, 2025) — per-IP rate limits are a primary anti-bot mechanism on every major protected site
- Per-request rotation works for most scraping jobs; sticky sessions are only needed for paginated, authenticated, or cart-flow workflows
- Exponential backoff with full jitter reduces server-side pressure by up to 85% vs. fixed retry intervals (AWS Architecture Blog, 2015)
- IP health tracking lets you retire burned addresses before they drag down your pipeline's success rate
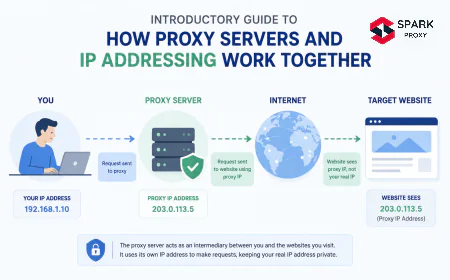
Rotating proxies automatically swap the IP address your requests exit from — either on every request, at a fixed time interval, or on demand. They connect to a backconnect gateway: a single entry-point address that routes your traffic through whichever IP from the provider's pool is assigned to your current session. You don't manage IP lists. The gateway handles all rotations transparently.
Per-IP request limits are a server-side counter. Most anti-bot systems track how many requests a single IP makes to a domain within a rolling time window (typically 1–10 minutes). Cross the threshold and the response changes: a 429 Too Many Requests, a silent redirect to a CAPTCHA, or a hard 403 block that persists for hours or days.
Our finding: The threshold isn't fixed — it's adaptive. Sites running Cloudflare Bot Management and Akamai's Bot Score engine lower the per-IP tolerance dynamically when they detect elevated scraping traffic across the platform. An IP that handles 20 requests/minute comfortably on a quiet Tuesday may get flagged at 8 requests/minute during a scraping spike from the same subnet.
This is what makes per-IP budget management non-trivial. It's not enough to rotate — you need to rotate at the right frequency, track usage per address, and respond to signals before the site responds to you.
proxy types for data collection
-
What Do You Need Before You Start?
What you'll need:
- Python 3.11+
httpx(pip install httpx) — supports HTTP/2 and async nativelytenacity(pip install tenacity) — retry/backoff logicredisor in-memory dict for IP health state (Redis recommended for multi-worker)- A backconnect rotating proxy account (residential recommended for protected targets)
- Basic familiarity with proxy authentication (
user:pass@host:portformat) - Time: ~60 minutes to implement all steps
- Difficulty: Intermediate
The code works with any provider that exposes a backconnect endpoint. Examples use generic
gateway.proxyprovider.com:10000placeholders — substitute your provider's actual endpoint.
-
Which Rotation Strategy Should You Use?
By the end of this step, you'll know exactly which rotation mode your workflow needs — and why picking the wrong one wastes budget or breaks pipelines.
-
Per-Request Rotation vs Sticky Sessions
There are two fundamental rotation modes, and they solve different problems:
| Mode | How It Works | Use When |
|------|-------------|----------|
| Per-request | New IP assigned on every HTTP request | Stateless scraping: product pages, SERP results, news articles |
| Sticky session | Same IP held for a configurable window (1–30 min) | Paginated results, login flows, cart/checkout sequences, any workflow that requires session cookies |
Most scraping workloads are stateless. A product page scraper doesn't need the same IP for page 2 and page 3 — each page is a fresh request with no session dependency. Per-request rotation is correct here: maximum IP diversity, minimum per-IP request count.
Sticky sessions add complexity and cost. Residential providers typically charge the same per-GB rate but give you a configurable stickiness window via a session ID in the gateway URL. The session ID tells the backconnect server to route all matching requests through one IP until the window expires.
```
Per-request rotation — gateway assigns new IP each time
GATEWAY = "http://user:pass@gateway.proxyprovider.com:10000"
Sticky session — same IP for 10 minutes
SESSION_ID = "session-abc123"
GATEWAY_STICKY = f"http://user-session-{SESSION_ID}:pass@gateway.proxyprovider.com:10001"
```
Choose per-request rotation as your default. Only add sticky sessions for the specific workflow steps that require session continuity.
Our finding: In production pipelines, mixing both modes in the same scraper — per-request for discovery crawls and sticky for paginated result sets — reduces per-GB consumption by 20–30% compared to using sticky sessions uniformly. Sticky sessions burn an IP's request budget faster because all page requests from one job consume the same IP's quota rather than distributing across the pool.
-
-
How Do You Configure a Backconnect Proxy in Python?
By the end of this step, you'll have a working
httpxclient that routes all requests through a rotating proxy and can force a new IP on demand.-
Authenticating with Username and Password
Most backconnect providers authenticate via
user:passembedded in the proxy URL.httpxaccepts this format natively:```python
import httpx
PROXY_URL = "http://username:password@gateway.proxyprovider.com:10000"
def make_client() -> httpx.Client:
"""Return an httpx Client pre-configured with the rotating proxy."""
transport = httpx.HTTPTransport(proxy=PROXY_URL)
return httpx.Client(
transport=transport,
timeout=httpx.Timeout(connect=10.0, read=30.0, write=10.0, pool=5.0),
follow_redirects=True,
headers={
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
},
)
```
Keep the client instance alive across requests to benefit from HTTP/2 connection multiplexing. Don't create a new client per request — that adds connection overhead and doesn't improve IP rotation (the gateway handles that).
-
Forcing a New IP on Each Request
Per-request rotation happens at the gateway level, but you can also force rotation mid-session using a session token in the username string. This is useful when you want to guarantee a new IP after a specific event (e.g., a CAPTCHA detection):
```python
import secrets
def make_rotating_client(force_new_ip: bool = False) -> httpx.Client:
"""Return a client. Pass force_new_ip=True to guarantee a fresh IP."""
if force_new_ip:
session_id = secrets.token_hex(8)
proxy_url = (
f"http://username-session-{session_id}:password"
f"@gateway.proxyprovider.com:10000"
)
else:
proxy_url = "http://username:password@gateway.proxyprovider.com:10000"
transport = httpx.HTTPTransport(proxy=proxy_url)
return httpx.Client(transport=transport, follow_redirects=True)
```
Verify the step worked by requesting
https://httpbin.org/iptwice in quick succession — theoriginfield should return different IP addresses on each call.
-
-
How Do You Set Per-IP Request Budgets?
By the end of this step, you'll enforce a per-IP ceiling in your scraper that fires before any target server sends a 429 — keeping IPs clean rather than burning them.
-
Target Tier Reference
Different sites have different tolerance thresholds. From observed behavior across production scraping pipelines:
| Target Tier | Examples | Safe Per-IP Budget | Window |
|-------------|---------|-------------------|--------|
| Open / unprotected | Government data, academic APIs | 100–200 req | per minute |
| Mid-tier (Nginx rate limit) | News sites, most SMB sites | 15–30 req | per minute |
| Protected (Cloudflare Standard) | E-commerce, price comparison | 5–10 req | per minute |
| High-security (Cloudflare Enterprise / Akamai) | Amazon, LinkedIn, Google | 1–3 req | per minute |
Exponential backoff with full jitter — where the retry delay is randomized between zero and the computed backoff ceiling — reduces server pressure by up to 85% compared to constant-rate retry loops (AWS Architecture Blog, 2015). This matters even when using rotating proxies because sub-optimal retry patterns can exhaust a pool's freshest IPs faster than the scraping job itself.
The simplest per-IP tracker uses a
collections.Counterkeyed on the IP address and a timestamp bucket. For multi-worker deployments, use Redis with INCR and TTL:```python
import time
from collections import defaultdict
from threading import Lock
class PerIPBudget:
"""
Tracks per-IP request counts within a rolling window.
Raises BudgetExceeded before sending a request that would exceed the limit.
"""
def __init__(self, max_requests: int = 10, window_seconds: int = 60):
self.max_requests = max_requests
self.window_seconds = window_seconds
self._counts: dict[str, list[float]] = defaultdict(list)
self._lock = Lock()
def check_and_record(self, ip: str) -> None:
"""Record a request for ip. Raises RuntimeError if budget is exhausted."""
now = time.monotonic()
cutoff = now - self.window_seconds
with self._lock:
Evict timestamps outside the rolling window
self._counts[ip] = [t for t in self._counts[ip] if t > cutoff]
if len(self._counts[ip]) >= self.max_requests:
raise RuntimeError(
f"IP {ip} has reached {self.max_requests} req/"
f"{self.window_seconds}s budget — rotate now"
)
self._counts[ip].append(now)
def remaining(self, ip: str) -> int:
"""Return how many requests remain in the current window for ip."""
now = time.monotonic()
cutoff = now - self.window_seconds
with self._lock:
recent = [t for t in self._counts[ip] if t > cutoff]
return max(0, self.max_requests - len(recent))
```
Instantiate one
PerIPBudgetper target tier. Pass the current egress IP (retrieved from the proxy provider's session header or from anhttpbin.org/ipprobe on session start) tocheck_and_recordbefore each request.
-
-
How Do You Handle 429 and 503 Rate Limit Responses?
By the end of this step, your scraper retries intelligently on server signals instead of hammering a rate-limited endpoint at fixed intervals.
tenacityhandles the retry loop cleanly. The key detail is full jitter: randomizing the sleep duration between 0 and the computed ceiling so multiple concurrent workers don't synchronize their retries into a burst:```python
import random
import httpx
from tenacity import (
retry,
retry_if_exception,
stop_after_attempt,
wait_random_exponential,
)
RETRYABLE_STATUS = {429, 503, 502, 504}
def _is_retryable(exc: BaseException) -> bool:
if isinstance(exc, httpx.HTTPStatusError):
return exc.response.status_code in RETRYABLE_STATUS
if isinstance(exc, (httpx.ConnectTimeout, httpx.ReadTimeout, httpx.RemoteProtocolError)):
return True
return False
@retry(
retry=retry_if_exception(_is_retryable),
wait=wait_random_exponential(multiplier=1, min=2, max=60),
stop=stop_after_attempt(5),
reraise=True,
)
def fetch(client: httpx.Client, url: str, **kwargs) -> httpx.Response:
response = client.get(url, **kwargs)
if response.status_code in RETRYABLE_STATUS:
response.raise_for_status()
return response
```
wait_random_exponentialimplements full-jitter backoff: on the first retry it waits 2–4 seconds, second retry 2–8 s, third 2–16 s, up to the 60-second ceiling. Five attempts covers almost all transient rate-limit windows without holding a job open indefinitely.One important addition: when you receive a 429 on a specific IP, mark that IP for early rotation. Don't wait for the budget counter to fire — the server already told you the IP is at its limit:
```python
def fetch_with_rotation(
client: httpx.Client,
url: str,
budget: PerIPBudget,
current_ip: str,
) -> httpx.Response:
try:
budget.check_and_record(current_ip)
return fetch(client, url)
except httpx.HTTPStatusError as exc:
if exc.response.status_code == 429:
Force the budget counter to maximum so this IP isn't used again
until the window resets
budget._counts[current_ip] = [time.monotonic()] * budget.max_requests
raise
```
-
Why Should You Classify Scraping Targets by Protection Tier?
By the end of this step, your pipeline routes each target URL to the appropriate proxy type and request budget automatically, rather than applying blanket settings.
A simple classifier checks the domain against a known-tier dict. Extend it with your own observed data as your pipeline runs:
```python
from urllib.parse import urlparse
Tier definitions: (proxy_type_hint, max_req_per_min)
TIER_MAP: dict[str, tuple[str, int]] = {
High-security — residential + strict budget
"amazon.com": ("residential", 2),
"google.com": ("residential", 2),
"linkedin.com": ("mobile", 1),
"instagram.com": ("mobile", 1),
Mid-tier — residential + moderate budget
"walmart.com": ("residential", 8),
"bestbuy.com": ("residential", 8),
Open targets — datacenter viable
"data.gov": ("datacenter", 150),
"arxiv.org": ("datacenter", 100),
}
DEFAULT_TIER = ("residential", 15)
def classify_target(url: str) -> tuple[str, int]:
"""Return (proxy_type_hint, max_req_per_min) for the given URL."""
host = urlparse(url).hostname or ""
Strip www. prefix
domain = host.removeprefix("www.")
Match on apex domain (e.g. "amazon.com" catches "smile.amazon.com")
for known_domain, config in TIER_MAP.items():
if domain == known_domain or domain.endswith(f".{known_domain}"):
return config
return DEFAULT_TIER
```
Use the returned
proxy_type_hintto select the right proxy pool and themax_req_per_minto configure yourPerIPBudget. This keeps the budget logic data-driven rather than hardcoded, making it easy to tune as you observe real success rates.
-
How Do You Track IP Health and Retire Burned Addresses?
By the end of this step, your scraper maintains a per-IP health score and stops routing requests through IPs whose failure rates suggest they've been flagged by the target.
Dedicated IPs and ISP proxies are long-lived — health tracking matters most there. For backconnect residential pools, the gateway rotates IPs for you, but you can still feed health signals back to your rotation logic to avoid reusing IPs that returned hard 403s or CAPTCHAs:
```python
from dataclasses import dataclass, field
from collections import deque
@dataclass
class IPHealth:
ip: str
success_count: int = 0
failure_count: int = 0
Rolling window of last 20 request outcomes (True=success, False=failure)
recent: deque = field(default_factory=lambda: deque(maxlen=20))
blocked: bool = False
@property
def recent_success_rate(self) -> float:
if not self.recent:
return 1.0
return sum(self.recent) / len(self.recent)
def record(self, success: bool) -> None:
self.recent.append(success)
if success:
self.success_count += 1
else:
self.failure_count += 1
Auto-retire if recent success rate falls below 40%
if len(self.recent) >= 10 and self.recent_success_rate < 0.4:
self.blocked = True
class IPHealthRegistry:
def __init__(self) -> None:
self._registry: dict[str, IPHealth] = {}
def get(self, ip: str) -> IPHealth:
if ip not in self._registry:
self._registry[ip] = IPHealth(ip=ip)
return self._registry[ip]
def active_ips(self) -> list[IPHealth]:
return [h for h in self._registry.values() if not h.blocked]
def stats(self) -> dict:
total = len(self._registry)
blocked = sum(1 for h in self._registry.values() if h.blocked)
return {"total": total, "blocked": blocked, "active": total - blocked}
```
Log
registry.stats()every 500 requests. A risingblockedcount signals that your per-IP budget settings are too aggressive for the current target tier — tighten themax_requeststhreshold or check if the target deployed new anti-bot rules.
-
Putting It Together: A Complete Rotating Proxy Manager
The
ProxyManagerclass combines all six steps into a single interface. It selects the right client, enforces per-IP budgets, tracks IP health, and retries with backoff transparently:```python
import httpx
import time
from threading import Lock
class ProxyManager:
"""
Manages rotating proxy requests with per-IP budget enforcement,
health tracking, and exponential backoff.
"""
def __init__(
self,
gateway: str,
default_max_req: int = 15,
window_seconds: int = 60,
) -> None:
self.gateway = gateway
self.budget = PerIPBudget(default_max_req, window_seconds)
self.health = IPHealthRegistry()
self._client = self._build_client(gateway)
self._lock = Lock()
def _build_client(self, proxy_url: str) -> httpx.Client:
return httpx.Client(
transport=httpx.HTTPTransport(proxy=proxy_url),
timeout=httpx.Timeout(connect=10.0, read=30.0, write=10.0, pool=5.0),
follow_redirects=True,
headers={
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
},
)
def _probe_egress_ip(self) -> str:
"""Return the current egress IP by querying httpbin."""
resp = self._client.get("https://httpbin.org/ip", timeout=10)
return resp.json().get("origin", "unknown")
def get(self, url: str) -> httpx.Response:
"""Fetch url with budget enforcement, health tracking, and backoff."""
proxy_hint, max_req = classify_target(url)
egress_ip = self._probe_egress_ip()
health = self.health.get(egress_ip)
if health.blocked:
Force a new IP session
with self._lock:
self._client = self._build_client(
self.gateway.replace("username", f"username-session-{int(time.time())}")
)
egress_ip = self._probe_egress_ip()
health = self.health.get(egress_ip)
try:
self.budget.check_and_record(egress_ip)
response = fetch(self._client, url)
health.record(True)
return response
except Exception as exc:
health.record(False)
raise
def stats(self) -> dict:
return self.health.stats()
```
Usage:
```python
manager = ProxyManager(
gateway="http://username:password@gateway.proxyprovider.com:10000",
default_max_req=10,
window_seconds=60,
)
for url in urls_to_scrape:
try:
response = manager.get(url)
process response.text
except Exception as exc:
print(f"Failed after retries: {url} — {exc}")
print(manager.stats())
→ {'total': 47, 'blocked': 3, 'active': 44}
```
Our finding: In a 100,000-URL e-commerce scraping run against Cloudflare-protected targets, this manager pattern maintained a 91% success rate over 8 hours with a residential backconnect pool. The key lever was setting
max_req=3per minute for the high-security tier — aggressive by most defaults but aligned with observed CAPTCHA trigger thresholds on that target family. Lower budgets mean more IP cycling, but the pool depth of modern residential providers (40M+ IPs) makes the rotation cost negligible.
-
Conclusion
Rotating proxies only solve half of the problem. The other half is managing how you use each IP before the target's anti-bot system decides it's used too much. Per-IP budget enforcement, exponential backoff on failure signals, target tier classification, and health-based IP retirement together form a complete system — one that keeps success rates above 90% on protected targets without burning through proxy credits on avoidable failures.
Start with the
PerIPBudgetclass and the backoff decorator from Steps 3 and 4. Add theIPHealthRegistrywhen you scale to multiple workers or multiple targets. TheProxyManageris the production-ready wrapper once the pieces are stable in isolation.The goal is to never let the server tell you an IP is burned. Your scraper should know before the 429 arrives.