


Using Proxies for Review Monitoring and Sentiment Analysis
93% of consumers read reviews before buying. Learn how a review monitoring proxy enables continuous scraping of Google, Yelp, Amazon, and Trustpilot for sentiment analysis, competitor tracking, and brand reputation management.

Table of Contents
- Why Businesses Need Proxy Infrastructure for Review Monitoring
- What Is a Review Monitoring Proxy?
- Which Review Platforms Require Proxy Rotation for Scraping?
- How Do You Build a Review Scraper with Proxy Rotation?
- What Sentiment Signals Can You Extract from Scraped Reviews?
- What Are the Legal and Ethical Considerations for Review Scraping?
- Conclusion
-
Why Businesses Need Proxy Infrastructure for Review Monitoring
Using Proxies for Review Monitoring and Sentiment Analysis
A review monitoring proxy is the infrastructure layer that makes continuous, large-scale review collection from platforms like Google, Amazon, Yelp, and Trustpilot operationally viable. Without rotating IPs, review scraping programs hit rate limits, IP bans, and CAPTCHAs within hours of starting a monitoring cycle — breaking the continuous data feed that sentiment analysis pipelines depend on.
The stakes are concrete. 93% of consumers read online reviews before making a purchase (BrightLocal, 2024), and 87% will not consider a business rated below four stars (BrightLocal, 2024). Businesses that monitor and respond to reviews see 35% higher conversion rates than those that do not (Harvard Business Review, 2022). For brands with hundreds of product SKUs or multi-location footprints, manual review monitoring is not a realistic option. Automated proxy-backed collection is the only scalable approach.
This guide covers the proxy architecture for review monitoring, which platforms respond well to datacenter proxy rotation, how to build the collection and sentiment pipeline, and what legal boundaries apply to automated review scraping.
Key Takeaways
- 93% of consumers read reviews before purchasing (BrightLocal, 2024). Review data is one of the highest-signal inputs for brand health and competitive intelligence programs
- 87% of consumers avoid businesses with ratings below 4 stars (BrightLocal, 2024). Monitoring rating velocity across platforms gives early warning of reputation events
- Businesses that respond to reviews see 35% higher conversion rates (Harvard Business Review, 2022). Proxy-backed monitoring enables response at scale for multi-location and multi-SKU brands
- Over 4.2 trillion reviews are indexed across Google's global platform (Statista, 2024). The volume of review data available makes automated collection the only viable approach to competitive sentiment analysis
- The FTC issued $43M in penalties for fake review practices in 2024 (FTC, 2024). Brand teams increasingly use sentiment proxies to detect competitor fake review campaigns
Review platforms are adversarial scraping environments. Google, Amazon, Yelp, Trustpilot, and G2 invest heavily in bot detection because a large fraction of the traffic that hits their review endpoints is automated. Their defenses — IP-based rate limits, behavioral fingerprinting, JavaScript challenges, CAPTCHAs, and session token requirements — make sustained collection from static IPs or small IP pools nearly impossible beyond the first few hundred requests per day.
For a brand managing 50 product SKUs across five platforms, maintaining real-time sentiment visibility requires thousands of review page requests per monitoring cycle. A small business tracking a single Google My Business location across three competitor locations might need 200-400 requests per cycle to keep review feeds current. Both scenarios exceed the per-IP rate limits that major platforms enforce.
Three operational requirements drive proxy adoption for review monitoring:
Volume beyond per-IP rate limits: Major review platforms apply per-IP rate limits in the range of 50-300 requests per hour before triggering soft blocks (delayed responses, degraded results) and eventual hard blocks (IP bans). A rotating pool of datacenter IPs distributes request volume so no single IP approaches the detection threshold.
Geo-targeted review collection: Reviews on platforms like Google and Yelp are localized. A restaurant chain monitoring customer sentiment across 40 US markets cannot reliably collect location-specific reviews from a single geographic IP. Geo-targeted proxy IPs in each market retrieve the correct localized review content rather than the default content served to out-of-area IPs.
Continuous monitoring without session burns: Sentiment analysis pipelines depend on continuous data flow. A monitoring cycle that breaks because a static IP hit a rate limit creates coverage gaps that may miss a negative review surge, a competitor fake review campaign, or a product complaint pattern that needs rapid response. Proxy rotation ensures that collection continues even when individual IPs are temporarily throttled.
What we've found: The most commonly misconfigured aspect of review monitoring proxy setups is treating all platforms identically. Google review pages, Amazon product reviews, and Yelp business listings have meaningfully different scraping profiles: Google uses JavaScript rendering with dynamic pagination that requires headless browser session management; Amazon enforces aggressive per-IP limits but tolerates moderate request rates with appropriate User-Agent rotation; Yelp employs behavior-based detection that flags unusually uniform inter-request timing even with different IPs. Optimal collection requires per-platform configuration profiles rather than a one-size-fits-all proxy rotation strategy.
-
What Is a Review Monitoring Proxy?
A review monitoring proxy is a rotating proxy server — typically a datacenter IP pool — used to route automated review collection requests through multiple IP addresses to avoid platform-level rate limits and detection. It provides the infrastructure layer that makes continuous, large-scale review scraping viable across multiple platforms simultaneously.
In a review monitoring program, proxy infrastructure serves three distinct functions:
Request distribution across IP pool: Each review page request is routed through a different IP address, distributing volume so no single IP accumulates enough requests to trigger rate limiting or behavioral detection algorithms. The proxy rotates IPs either per-request (highest distribution) or per-session (useful for multi-page pagination where session continuity matters).
Geolocation targeting: Review content is localized on most major platforms. A proxy pool with IPs in specific US cities or countries retrieves the correct geographic review context — local search rankings, location-specific reviews, and regional rating aggregates — rather than generic or anonymized content.
Session management for JavaScript-rendered platforms: Google reviews and several other major platforms require JavaScript execution to render review content. A review monitoring proxy configured with headless browser sessions (Playwright or Puppeteer) handles cookie persistence, scroll-triggered pagination, and dynamic content loading across rotating IPs.
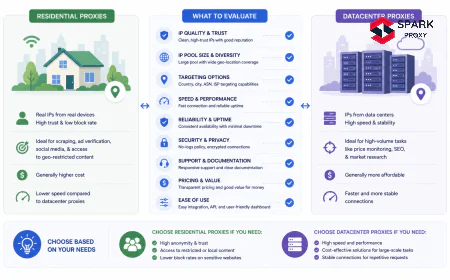
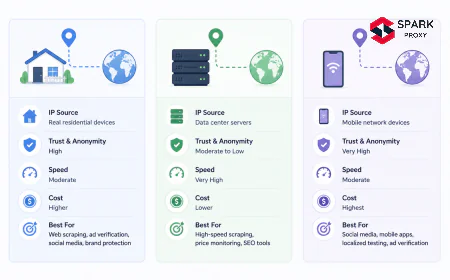
residential vs datacenter proxies
-
Which Review Platforms Require Proxy Rotation for Scraping?
Source: BrightLocal Consumer Review Survey, 2024; Statista, 2024. Difficulty ratings based on observed bot detection aggressiveness and documented proxy scraping community experience per platform. Platform-specific notes for proxy configuration:
Google Reviews are the most operationally demanding. Review content renders via JavaScript within Google Maps embed responses, requiring headless browser session management rather than simple HTTP requests. Request volume for a single business listing is manageable; collecting across hundreds of competitor locations requires rotating IPs with geo-matching to retrieve correctly localized results.
Amazon Reviews are high-volume and high-friction. Amazon applies aggressive per-IP rate limits and uses behavioral signals (request patterns, header consistency, timing uniformity) to detect automation. Collecting reviews across large product catalogs requires rotation per request, randomized timing with high variance, and consistent browser header sets.
Yelp uses behavior-based detection that flags uniform inter-request timing even across different IPs. Randomizing request delays with a wide distribution is as important as IP rotation for Yelp collection. The Yelp Fusion API provides structured access for modest volumes and is worth using as the primary collection method, with proxy-based scraping as supplemental coverage.
Trustpilot provides a public API with reasonable rate limits, making it the least reliant on proxy-based scraping of the major platforms. Proxy-backed collection is most useful for bulk historical collection or monitoring of competitor profiles at volumes that exceed API tier limits.
using proxies for brand protection
-
How Do You Build a Review Scraper with Proxy Rotation?
-
Handling the Sentiment Analysis Pipeline
A production review monitoring system has two components: the collection layer (proxy-backed scraping) and the analysis layer (NLP-based sentiment classification). The collection layer feeds structured review data to the analysis layer on a continuous basis. Here is a complete implementation covering both:
```python
import requests
import random
import time
import json
import re
import logging
from dataclasses import dataclass, field
from datetime import datetime
from typing import Optional
from bs4 import BeautifulSoup
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
── Proxy pool ─────────────────────────────────────────────────────────────────
PROXY_POOL = [
"http://user:pass@proxy1:port",
"http://user:pass@proxy2:port",
"http://user:pass@proxy3:port",
"http://user:pass@proxy4:port",
"http://user:pass@proxy5:port",
]
def get_proxy() -> dict:
"""Return a randomly selected proxy from the pool."""
p = random.choice(PROXY_POOL)
return {"http": p, "https": p}
── Request headers ────────────────────────────────────────────────────────────
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
]
def get_headers() -> dict:
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,/;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Cache-Control": "no-cache",
}
── Review data model ──────────────────────────────────────────────────────────
@dataclass
class Review:
platform: str
business_id: str
review_id: str
rating: float # 1.0 - 5.0
text: str
date: str
author: str = ""
sentiment: str = "" # "positive" | "neutral" | "negative"
sentiment_score: float = 0.0 # -1.0 to +1.0
keywords: list[str] = field(default_factory=list)
── Trustpilot scraper (HTML, no auth wall) ────────────────────────────────────
def scrape_trustpilot(company_domain: str, max_pages: int = 5) -> list[Review]:
"""
Scrape Trustpilot reviews for a company domain.
Rotates proxy and User-Agent per page request.
"""
reviews: list[Review] = []
base_url = f"https://www.trustpilot.com/review/{company_domain}"
for page in range(1, max_pages + 1):
url = f"{base_url}?page={page}" if page > 1 else base_url
try:
resp = requests.get(
url,
headers=get_headers(),
proxies=get_proxy(),
timeout=15,
)
resp.raise_for_status()
except requests.RequestException as e:
logging.warning(f"Trustpilot page {page} failed: {e}")
break
soup = BeautifulSoup(resp.text, "html.parser")
Parse review cards from Trustpilot HTML structure
for card in soup.select('[data-service-review-card-paper]'):
try:
rating_el = card.select_one('[data-service-review-rating]')
text_el = card.select_one('[data-service-review-text-typography]')
date_el = card.select_one('time')
author_el = card.select_one('[data-consumer-name-typography]')
if not (rating_el and text_el):
continue
Extract numeric rating from aria-label: "Rated 4 out of 5 stars"
rating_match = re.search(r'Rated\s+(\d)', rating_el.get('aria-label', ''))
rating = float(rating_match.group(1)) if rating_match else 0.0
reviews.append(Review(
platform="trustpilot",
business_id=company_domain,
review_id=card.get('data-review-id', f"tp_{page}_{len(reviews)}"),
rating=rating,
text=text_el.get_text(strip=True),
date=date_el.get('datetime', '') if date_el else '',
author=author_el.get_text(strip=True) if author_el else '',
))
except Exception as e:
logging.debug(f"Review parse error: {e}")
continue
logging.info(f"Trustpilot {company_domain}: page {page} -> {len(reviews)} reviews so far")
Respectful inter-page delay with high variance
time.sleep(random.uniform(3.0, 8.0))
return reviews
── Rule-based sentiment classifier ───────────────────────────────────────────
POSITIVE_TERMS = {
"excellent", "great", "love", "amazing", "perfect", "outstanding",
"fantastic", "recommend", "best", "happy", "satisfied", "impressed",
"wonderful", "easy", "fast", "helpful", "reliable", "efficient",
}
NEGATIVE_TERMS = {
"terrible", "awful", "horrible", "worst", "bad", "poor", "broken",
"useless", "waste", "disappointed", "slow", "difficult", "unreliable",
"unprofessional", "scam", "avoid", "frustrating", "misleading",
}
def classify_sentiment(review: Review) -> Review:
"""
Classify sentiment using rating + keyword signals.
Replace with a transformer model (e.g. cardiffnlp/twitter-roberta-base-sentiment)
for production accuracy.
"""
text_lower = review.text.lower()
words = set(re.findall(r'\b\w+\b', text_lower))
pos_hits = words & POSITIVE_TERMS
neg_hits = words & NEGATIVE_TERMS
Rating-weighted score: rating contributes 60%, keyword signal 40%
rating_score = (review.rating - 3.0) / 2.0 # normalize to -1..+1
keyword_score = (len(pos_hits) - len(neg_hits)) / max(len(pos_hits) + len(neg_hits), 1)
composite = 0.6 rating_score + 0.4 keyword_score
if composite > 0.2:
sentiment = "positive"
elif composite < -0.2:
sentiment = "negative"
else:
sentiment = "neutral"
review.sentiment = sentiment
review.sentiment_score = round(composite, 3)
review.keywords = list(pos_hits | neg_hits)
return review
── Aggregation report ─────────────────────────────────────────────────────────
def aggregate_sentiment(reviews: list[Review]) -> dict:
"""Produce summary sentiment metrics from a review batch."""
if not reviews:
return {}
sentiments = [r.sentiment for r in reviews]
ratings = [r.rating for r in reviews]
all_keywords = [kw for r in reviews for kw in r.keywords]
Frequency count for top keywords
kw_freq: dict[str, int] = {}
for kw in all_keywords:
kw_freq[kw] = kw_freq.get(kw, 0) + 1
top_keywords = sorted(kw_freq, key=kw_freq.get, reverse=True)[:10]
return {
"total_reviews": len(reviews),
"avg_rating": round(sum(ratings) / len(ratings), 2),
"positive_pct": round(sentiments.count("positive") / len(sentiments) * 100, 1),
"neutral_pct": round(sentiments.count("neutral") / len(sentiments) * 100, 1),
"negative_pct": round(sentiments.count("negative") / len(sentiments) * 100, 1),
"top_keywords": top_keywords,
"collection_ts": datetime.now().isoformat(),
}
── Example run ───────────────────────────────────────────────────────────────
if __name__ == "__main__":
raw_reviews = scrape_trustpilot("example-company.com", max_pages=3)
classified = [classify_sentiment(r) for r in raw_reviews]
report = aggregate_sentiment(classified)
print(json.dumps(report, indent=2))
Save full review dataset for downstream NLP pipeline
with open("reviews_output.json", "w") as f:
json.dump([vars(r) for r in classified], f, indent=2)
```
Key implementation decisions:
Rotate proxy per page, not per request: For paginated review collection, rotating IPs per page (rather than per individual element request) reduces the pool consumption rate while still distributing volume below per-IP thresholds. Only switch to per-request rotation for platforms with very aggressive per-IP limits (Amazon, Google).
Randomize both User-Agent and timing per request: Review platforms fingerprint scrapers partly through User-Agent uniformity and partly through timing patterns. A scraper that cycles through three User-Agents in strict order with 5-second fixed intervals is detectable. Randomize both dimensions independently with sufficient variance.
Use rating-weighted composite for sentiment scoring: Pure keyword-based sentiment classifiers miss sarcasm and qualified praise. A composite of the numeric rating (which represents the reviewer's summary judgment) and keyword signals is more robust than keyword analysis alone for review-specific sentiment work. For production pipelines, fine-tuned transformer models (distilBERT, RoBERTa) significantly outperform keyword approaches on review-domain text.
how to rotate proxies in Python
-
-
What Sentiment Signals Can You Extract from Scraped Reviews?
Source: BrightLocal Consumer Review Survey, 2024; Harvard Business Review, 2022. Adoption rate among enterprise review monitoring programs by sentiment signal extraction capability. What we've found: The single most actionable signal from review monitoring is not average rating or aggregate sentiment score. It is rating velocity: the rate of change in star rating over a rolling 7-14 day window. A brand with a 4.3 average that is trending toward 4.0 over two weeks, driven by a cluster of 2-star reviews mentioning a specific product attribute, provides far more actionable information than the static average alone. Rating velocity detection requires continuous collection through a proxy-backed pipeline; periodic (weekly or monthly) scraping misses the velocity signal entirely.
The primary sentiment signals extractable from scraped review data, ranked by operational value:
Rating velocity and trend analysis: Tracking how a business's aggregate rating changes over time. A downward velocity trend is an early indicator of product quality issues, service degradation, or the onset of a coordinated negative review campaign. Requires time-series collection across multiple monitoring cycles.
Topic keyword extraction and frequency analysis: Identifying which product attributes, service aspects, or business features appear most frequently in positive vs. negative reviews. A sudden increase in the frequency of a specific negative keyword (e.g., "shipping delay", "packaging damaged") signals an operational problem that may not yet appear in aggregate metrics.
Competitive sentiment benchmarking: Collecting and classifying sentiment for competitor products or business locations alongside your own. Sentiment delta (your sentiment score minus competitor sentiment score) is a more actionable metric than absolute score, particularly for pricing and product positioning decisions.
Fake review anomaly detection: The FTC issued $43M in penalties for fake review practices in 2024 (FTC, 2024). Proxy-backed monitoring enables detection of unusual patterns in competitor review profiles: sudden spikes in five-star reviews within short time windows, clusters of structurally similar review texts, reviewer accounts with no review history outside the target business, and disproportionate volume on new product listings. These anomalies can be reported to platform trust and safety teams.
Aspect-based sentiment analysis (ABSA): Fine-grained sentiment classification that evaluates sentiment at the product attribute level rather than the overall review level. A review that rates a product four stars but explicitly expresses dissatisfaction with battery life and satisfaction with camera quality contains two distinct aspect-level signals. ABSA requires NLP models trained on review-domain data and is the most resource-intensive signal extraction capability.
using proxies for market research
-
What Are the Legal and Ethical Considerations for Review Scraping?
Review scraping occupies well-defined legal territory following the hiQ Labs v. LinkedIn precedent established by the Ninth Circuit Court of Appeals. The ruling held that scraping publicly accessible data does not constitute unauthorized access under the Computer Fraud and Abuse Act (CFAA). Review content on major platforms is generally publicly accessible: Google reviews, Yelp listings, Amazon product reviews, and Trustpilot pages are all available without authentication to any visitor. Scraping this public content through proxy IPs is not unauthorized computer access.
The legal framework has two practical limits:
Terms of service are contractual, not criminal: Platform terms of service that prohibit automated scraping are enforceable as civil contract claims, not criminal computer access violations. Violating a platform's ToS through automated scraping may expose a scraper to civil liability (injunctions, damages) but does not create CFAA criminal liability as long as the content is publicly accessible. The practical risk from ToS enforcement for most review monitoring use cases is IP blocking rather than litigation.
Personally identifiable information handling: Review text commonly contains reviewer names, which may be subject to data protection regulations (GDPR in the EU, CCPA in California). Processing and storing reviewer names as part of sentiment analysis pipelines requires compliance with applicable data protection frameworks: lawful basis for processing, appropriate retention limits, and data subject rights support. Most review monitoring programs handle this by anonymizing reviewer identifiers before storing scraped data.
Fake review detection and reporting: Using proxy-backed monitoring to identify and report fake review campaigns to platform operators is unambiguously lawful and consistent with platform policies. The ethical dimension is maintaining accurate detection standards: reporting competitor reviews to platforms requires confidence that the identified patterns actually represent inauthentic activity rather than legitimate review surges.
Proxy Infrastructure Built for Review Monitoring
SparkProxy's rotating datacenter pools support continuous review collection across Google, Amazon, Yelp, Trustpilot, and G2 with geo-targeted IPs for localized review access, per-request rotation for high-volume platforms, and session management for JavaScript-rendered review pages.
-
Conclusion
Over 4.2 trillion reviews are indexed across Google's platform alone (Statista, 2024). With 93% of consumers reading reviews before purchasing (BrightLocal, 2024) and 87% avoiding businesses below four stars, the business case for continuous review monitoring is straightforward. The infrastructure challenge is equally straightforward: review platforms invest heavily in bot detection because they understand what is at stake in their review data.
A review monitoring proxy addresses the infrastructure challenge with rotating IP pools that distribute collection volume below per-IP detection thresholds, geo-targeted addresses that retrieve correctly localized review content, and session management capabilities for JavaScript-rendered platforms like Google. The configuration specifics differ by platform: Amazon requires aggressive rotation and high-variance timing; Yelp requires variance in timing over consistency in IP rotation speed; Google requires headless browser session management regardless of proxy configuration.
The sentiment signals worth extracting from collected reviews, in order of operational value, are rating velocity trend (the most actionable early-warning signal), topic keyword frequency patterns, competitive sentiment delta, and fake review anomaly detection. Each requires continuous collection through a proxy-backed pipeline: periodic collection misses velocity signals entirely.
For brands running multi-location operations, managing large product catalogs, or conducting systematic competitive intelligence, proxy-backed review monitoring is the infrastructure that makes real-time reputation management operationally viable.
Frequently Asked Questions
A review monitoring proxy is a rotating datacenter IP pool used to route automated review scraping requests through multiple IP addresses, avoiding the rate limits and bot detection systems that major review platforms apply to high-volume collection. It enables continuous, large-scale review collection from platforms like Google, Amazon, Yelp, and Trustpilot for sentiment analysis, competitor tracking, and brand reputation management.
Google reviews require JavaScript execution to render, so plain HTTP requests return incomplete data. A datacenter proxy used in combination with a headless browser (Playwright or Puppeteer) handles the JavaScript rendering while rotating IPs manages Google's rate limiting. Geo-targeted proxy IPs in the relevant market are necessary when collecting location-specific review data from Google Maps.
The IP requirement depends on collection volume and platform mix. A single-brand monitoring program tracking 10-20 business locations across four platforms with hourly collection cycles typically requires 15-30 rotating IPs. A multi-brand competitive monitoring program collecting thousands of reviews per day across dozens of competitors may require 50-100+ IPs. Amazon and Google are the most IP-intensive platforms and should receive the largest share of the pool.
Scraping publicly accessible review content for business intelligence is not unauthorized computer access under the CFAA following the hiQ Labs v. LinkedIn Ninth Circuit ruling. Platform terms of service may prohibit automated scraping, creating civil contract risk rather than criminal liability. Review data containing personal information (reviewer names) requires GDPR/CCPA-compliant handling. Consult legal counsel for jurisdiction-specific guidance.
Proxy-backed review monitoring enables fake review detection by collecting competitor review profiles at high frequency and analyzing for anomaly patterns: sudden volume spikes within short windows, clusters of structurally similar review text (high cosine similarity between review embeddings), reviewer account profiles with no review history outside the target business, and rating distributions inconsistent with historical baseline. These anomaly signals can be reported to platform trust and safety teams with supporting data.